Tutorial & How‑to
4 min read
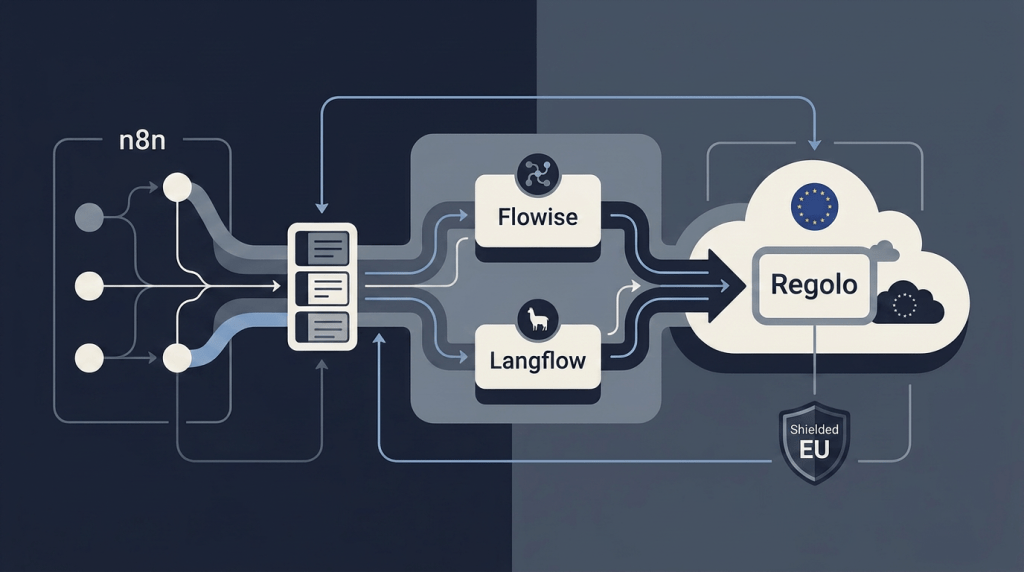
n8n, Flowise, and Langflow: Build AI Workflows without Sending Data Outside Europe
Low-code AI orchestration platforms like n8n, Flowise, and Langflow have made it incredibly easy to build complex AI agents. However, for European companies dealing…
Alex Genovese
Read article