Both models were released in June 2026, both carry a 1M-token context window, and both target the same enterprise buyer: teams that want frontier coding without paying closed-API rates.
The strategic split is clear: GLM-5.2 is the stronger model on text-only coding and agent reasoning; MiniMax M3 is the better choice when you need native multimodality, a much lower token bill, and faster long-context inference.
Model Overview at a Glance
| GLM-5.2 | MiniMax M3 | |
|---|---|---|
| Maker | Z.ai (Zhipu AI) | MiniMax (Shanghai) |
| Released | June 13, 2026 | June 1, 2026 |
| Architecture | MoE ~744B total / ~40B active | MoE ~428B total / ~23B active |
| Attention | Dense long-context | MiniMax Sparse Attention (MSA) |
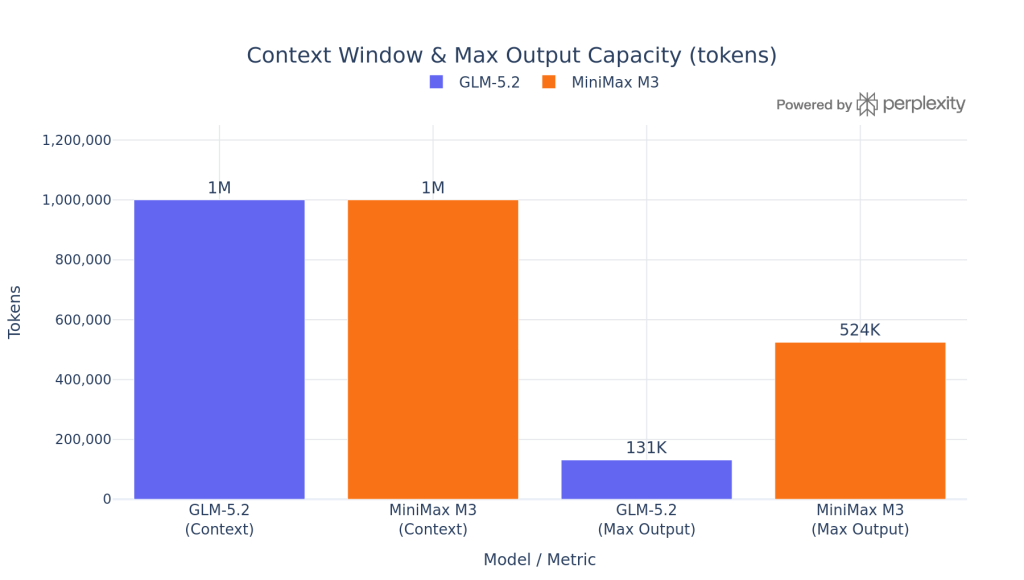
| Context window | 1M tokens | 1M tokens |
| Max output | 131,072 tokens | 524,288 tokens |
| Modality | Text only | Text + Image + Video |
| License | MIT | MiniMax Community License |
| API pricing (in/out) | $1.40 / $4.40 per 1M | $0.30 / $1.20 per 1M (≤512K) |
When to Use Each Model
Use GLM-5.2 when:
- The workload is pure text: repos, terminals, refactors, spec-to-code
- You need the highest open-weights coding leaderboard standing (Terminal-Bench 2.1: 82.7%, SWE-bench Pro: 62.1%)
- You run cache-heavy agent loops where the $0.26 cached-input rate applies
- You need MIT-licensed weights for unrestricted commercial deployment
Use MiniMax M3 when:
- Your workflow includes screenshots, design mockups, images, or video (screenshot-to-code, Figma-to-code)
- Cost-per-output-token is the binding constraint
- You fill the 1M context routinely and need MSA’s long-context efficiency
- You need long single-pass generation above 131K
- Agentic browsing is part of the task (BrowseComp: 83.5%)
Benchmark Overview
The composite scoring uses BenchLM’s provisional aggregate, pricing efficiency, context window, recency, output capacity, and versatility as weighted inputs.
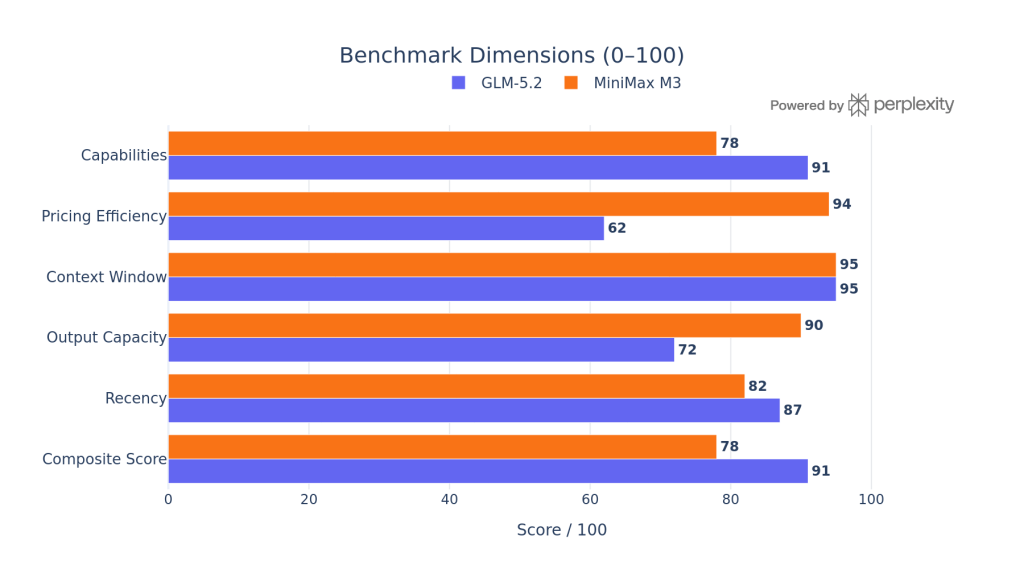
How to read it: GLM-5.2 leads on Capabilities (91 vs 78) and Composite Score (91 vs 78) per BenchLM’s provisional leaderboard. MiniMax M3 dominates on Pricing Efficiency (94 vs 62) and Output Capacity (90 vs 72), with identical Context Window scores since both publish 1M-token support.
Shared Benchmark Scores
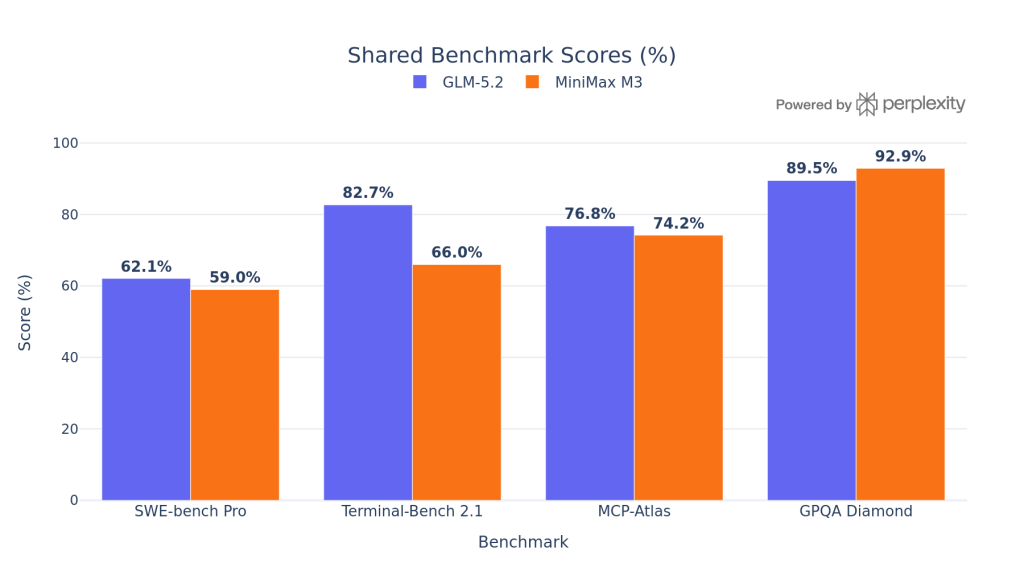
GLM-5.2 leads on SWE-bench Pro (62.1% vs 59.0%) and Terminal-Bench 2.1 (82.7% vs 66.0%), which is the single largest gap between the two models. MiniMax M3 edges ahead on GPQA Diamond (92.9% vs 91.2%), reflecting stronger general reasoning density.
Important caveat: the two labs ran on different harness versions for Terminal-Bench, so the 16.7-point gap should be read as directional, not a certified head-to-head.
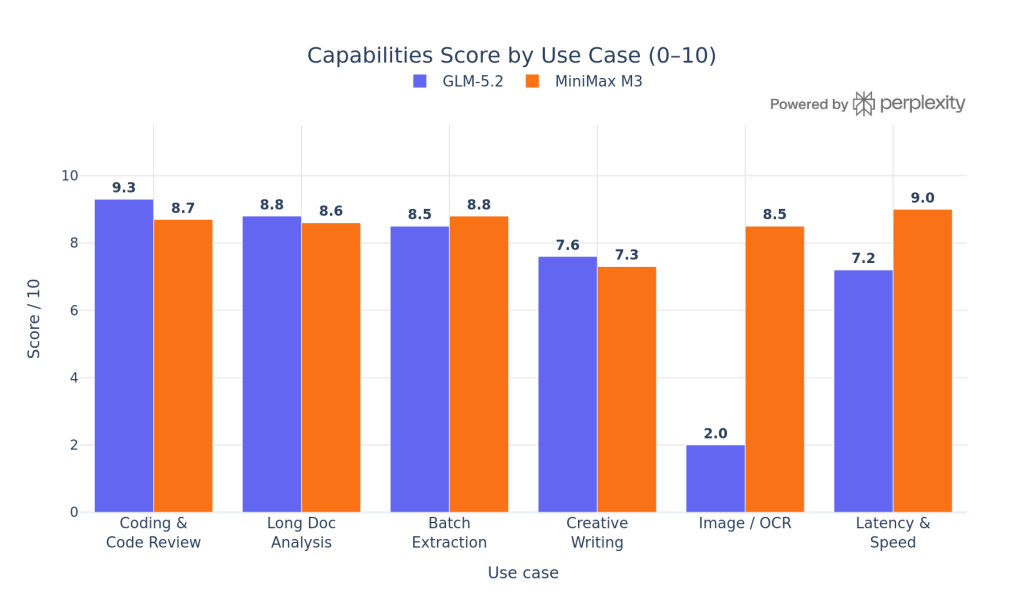
Capabilities Score by Use Case (0–10)
How each score was derived from public data:
| Use case | GLM-5.2 | MiniMax M3 | Driver |
|---|---|---|---|
| Coding & Code Review | 9.3 | 8.7 | GLM leads SWE-bench Pro (62.1 vs 59.0) and Terminal-Bench 2.1 (82.7 vs 66.0) |
| Long Doc Analysis | 8.8 | 8.6 | Both have 1M context; GLM’s dense attention is slightly more proven at 1M |
| Batch Extraction | 8.5 | 8.8 | M3’s 524K max output and MSA efficiency favor large batch jobs |
| Creative Writing | 7.6 | 7.3 | Neither is positioned as a writing-first model; GLM’s reasoning depth gives a slight edge |
| Image / OCR | 2.0 | 8.5 | GLM-5.2 is text-only; M3 natively supports image and video input |
| Latency & Speed | 7.2 | 9.0 | MSA delivers 9.7× faster prefill and 15.6× faster decoding at 1M context vs prior gen |
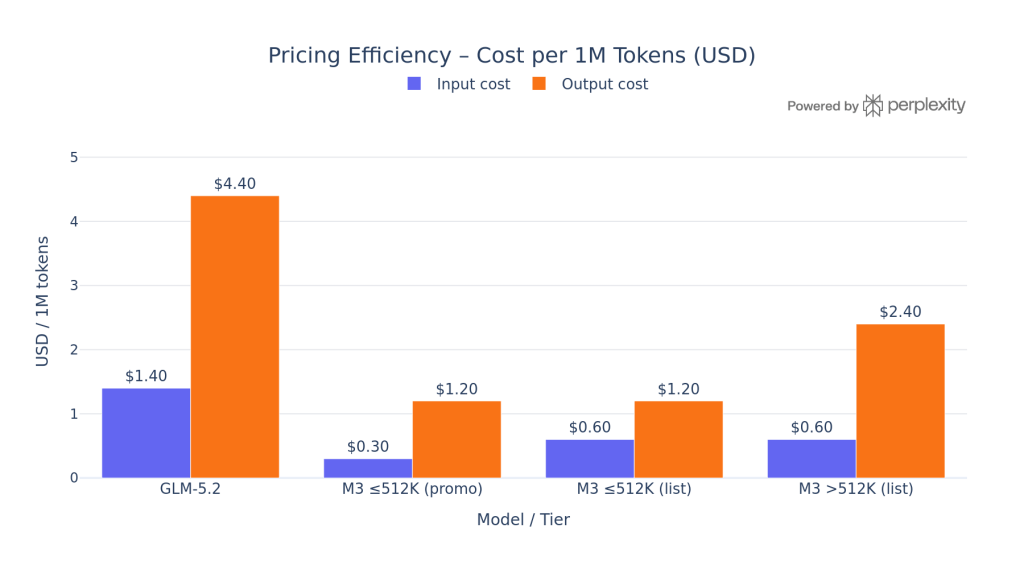
Pricing Efficiency
At list prices, MiniMax M3 is ~3.7× cheaper on output ($1.20 vs $4.40 per 1M tokens). For a team processing 50M output tokens per day, that gap is roughly $160K/month.
GLM-5.2 partially recovers through a $0.26 cached-input rate ($0.26/M vs M3’s $0.06/M), which benefits agent loops that re-send the same system prompt repeatedly.
Context Window & Max Output Capacity
Both models advertise a 1M-token context window, but they get there differently and offer very different output ceilings. GLM-5.2 caps output at 131K tokens per response; MiniMax M3 reaches 524K. For tasks that need to generate long code, detailed reports, or extended agent traces in a single call, M3’s output envelope is 4× larger.
Start your free 30-day trial at regolo.ai and deploy LLMs with complete privacy by design.
👉 Talk with our Engineers or Start your 30 days free →
- Discord – Share your thoughts
- GitHub Repo – Code of blog articles ready to start
- Follow Us on X @regolo_ai
- Open discussion on our Subreddit Community
Built with ❤️ by the Regolo team. Questions? regolo.ai/contact or chat with us on Discord