
Token cost optimization is no longer a side concern. In 2026, it is the control lever that separates scalable AI systems from budget black holes. Prices per token have dropped—dramatically—but total spend keeps climbing.
Agentic AI is the reason. Multi-step reasoning, tool use, retries, and verification loops multiply token usage. A simple prompt becomes a workflow. A workflow becomes a chain.
Table of Contents
- The Hidden Math Behind Exploding AI Bills
- What Actually Drives Token Usage in Modern Agentic Systems
- Practical Plays That Deliver Measurable Savings Without Sacrificing Quality
- How to Implement the Most Effective Token Cost Optimization Strategies
- Important Edge Cases and Gotchas That Most Teams Overlook
- FAQ
The Hidden Math Behind Exploding AI Bills
The mathematics of artificial intelligence deployment has created a situation where per-token prices continue to decline while overall expenditure climbs at an alarming rate for many organizations. This apparent contradiction stems from the fundamental change in how modern systems consume computational resources when moving from simple conversational interfaces to sophisticated agentic architectures that perform multi-step reasoning and tool orchestration.
Teams that initially celebrated dramatic reductions in token pricing quickly discovered that the total volume of tokens processed in production environments grows exponentially once autonomous agents enter the workflow and begin handling complex real-world tasks with branching logic and recovery mechanisms. One engineering group I followed closely reported that their AI infrastructure costs rose to represent between eighteen and twenty-seven percent of monthly burn rate during the second quarter of 2026 despite using models that were significantly cheaper on a per-token basis than previous generations.
Such patterns highlight why token cost optimization has rapidly evolved from an optional technical exercise into a critical business imperative that directly impacts runway sustainability and profitability timelines for both startups and established enterprises.
What Actually Drives Token Usage in Modern Agentic Systems
Agentic AI systems operate in ways that fundamentally differ from traditional single-turn language model interactions because they construct extended chains of thought that include planning stages followed by tool invocations verification loops and iterative refinement until the original objective reaches completion or acceptable quality thresholds.
This architectural approach multiplies token consumption dramatically compared to basic prompting strategies since each additional step in the reasoning process introduces new opportunities for both productive progress and wasteful repetition when the model encounters uncertainty or produces outputs that fail downstream validation checks.
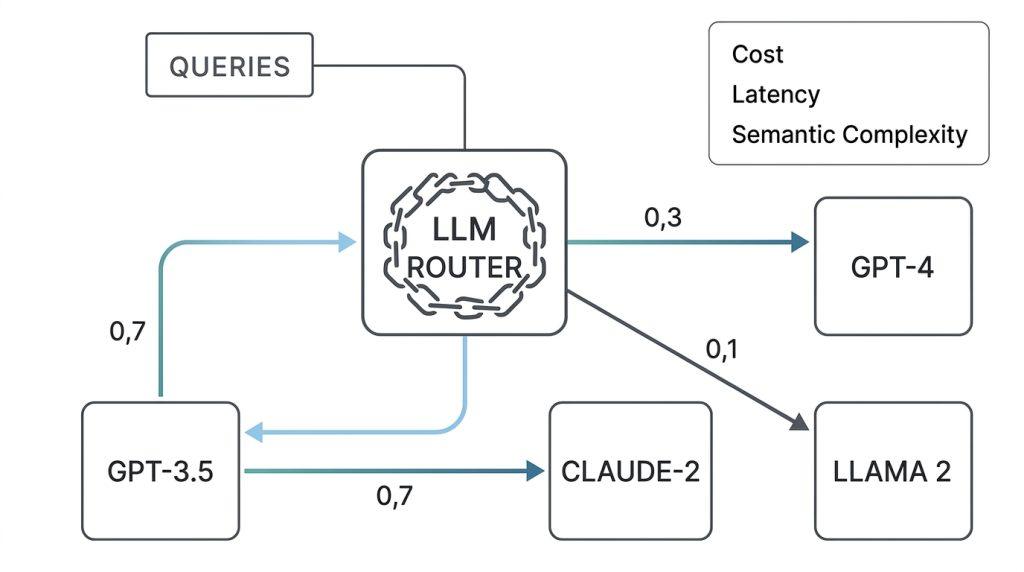
Smart routing combined with semantic caching offers teams powerful mechanisms to address these inefficiencies by directing different types of requests toward the most appropriate models while reusing previously computed results for semantically similar inputs that appear repeatedly across user sessions or internal workflows.
The value of implementing these techniques becomes clear when organizations measure not just raw token counts but actual cost per successfully completed task which often reveals substantial opportunities for improvement even when headline model pricing appears attractive on paper.
How to Implement the Most Effective Token Cost Optimization Strategies
Here is a practical breakdown of the strategies that deliver the biggest impact in 2026, with simple step-by-step mini-guides designed even for those who are not deep in the technical details.
1. Smart Routing (Model Routing) this technique automatically sends each request to the most appropriate model depending on complexity, instead of using the same expensive frontier model for everything.
- Start by classifying your prompts into simple, medium, and complex categories, or use semantic router like Brick to gateway your prompt to all the open source models hosted on our platform.
- If you continue in the manual way, you have to set rules or use a small classifier model that decides in real time: simple queries go to a cheap open-weight model (like GLM 5.2), while complex reasoning tasks use a more powerful one.
- Monitor results for two weeks and adjust the thresholds. Most teams see 30-50% savings within the first month, or in our paper we provided up to 80% on average of less costs (arxiv link).
2. Semantic Caching Instead of recomputing identical or very similar prompts every time, the system stores and reuses previous answers.
- Implement a caching layer that stores not just exact matches but semantically similar queries using embeddings.
- Set a TTL (time-to-live) based on how often your domain data changes.
- Start with a 24-48 hour cache window and measure the hit rate. Teams regularly achieve 50-60% cache hits on repetitive tasks such as support questions or code reviews.
3. Durable State Orchestrators: save the progress of your agents so they don’t have to restart everything from scratch after a failure or interruption.
- Replace stateless agent loops with frameworks that checkpoint state (conversation history, tool results, current plan).
- On failure, resume from the last checkpoint instead of re-running the full chain.
- This single change frequently cuts token usage by 40%+ on long-running tasks while improving reliability.
These four strategies, when combined, are what allow forward-thinking teams to reduce their AI spend by 40-75% while keeping or even improving output quality.
The Rapid Open-Weight Shift Reshaping Enterprise AI Infrastructure
The emergence of highly capable open-weight alternatives has accelerated the pace of change in how organizations think about LLM cost management because switching costs between different model providers remain relatively low when performance gaps continue narrowing across common use cases.
This commoditization dynamic puts sustained pressure on closed-source frontier providers to justify their premium pricing through demonstrably superior capabilities on the most challenging reasoning tasks while many production workloads migrate toward more economical options that organizations can fine-tune and run with greater control over both costs and data governance policies.
Hybrid architectures that combine open-weight models for high-volume routine operations with selective calls to frontier APIs for high-stakes decisions represent the most sustainable path forward for most enterprises that need both efficiency and peak performance depending on the specific requirements of each individual request.
Important Edge Cases and Gotchas That Most Teams Overlook
Aggressive prompt compression techniques sometimes introduce subtle quality degradations that trigger additional retry cycles which ultimately consume more tokens than the original uncompressed approach would have required in the first place.
Cache invalidation strategies become particularly tricky in domains where underlying data changes frequently because stale cached responses can lead to incorrect outputs that require expensive human review or additional verification steps downstream in the workflow.
Organizations that focus exclusively on minimizing total token volume without tracking cost per resolved outcome often miss important nuances where slightly higher token usage produces significantly more reliable results that deliver better overall business value when measured against actual objectives rather than purely computational metrics.
What nobody mentions in most public discussions involves the complex interplay between latency requirements and cost optimization decisions since user-facing applications cannot always tolerate the delays introduced by more economical but slower inference paths even when those paths would reduce monthly expenditure substantially.
FAQ
How much can token cost optimization realistically save?
Realistic range sits between 40% and 75% for most teams that move beyond basic prompt engineering. The upper end requires routing, caching, and some post-training. Quick wins like defaults and simple caches often deliver 25–35% with minimal code changes.
Does switching to open-weight models always make sense?
Not always. Workloads with heavy safety or reasoning requirements may still need frontier models for a subset of traffic. The winning pattern routes intelligently rather than going all-in on cheapest options.
What tools should teams adopt first for LLM cost tracking?
Start with something that gives per-request visibility and model routing. Many teams layer open-source observability on top of their gateway. The exact choice matters less than actually using the data to change behavior.
How do agentic systems change the token cost conversation?
They turn it from per-token accounting into cost-per-outcome. A system that uses more tokens but delivers reliable results faster often wins. Teams that keep measuring only tokens miss the bigger picture.
How much can serious token cost optimization efforts realistically save organizations in 2026?
Most teams that implement layered approaches including smart routing semantic caching and selective use of open-weight models achieve reductions between forty and seventy-five percent in AI-related spending while maintaining or even improving the quality and reliability of their agentic systems depending on the maturity of their implementation.
When does switching primarily to open-weight models make strategic sense for a given workload?
The decision depends heavily on the balance between safety requirements reasoning complexity and volume characteristics of the specific use case since many organizations benefit from hybrid strategies that reserve frontier models for the most demanding scenarios while directing the majority of traffic toward more economical open-weight alternatives that have been appropriately customized.
What should teams prioritize first when beginning their token cost optimization journey?
Initial efforts usually deliver the highest returns when focused on implementing proper observability for per-request costs combined with basic routing rules and semantic caching infrastructure before moving into more advanced areas such as custom post-training or durable state management for complex agents.
Start your free 30-day trial at regolo.ai and deploy LLMs with complete privacy by design.
👉 Talk with our Engineers or Start your 30 days free →
- Discord – Share your thoughts
- GitHub Repo – Code of blog articles ready to start
- Follow Us on X @regolo_ai
- Open discussion on our Subreddit Community
Built with ❤️ by the Regolo team. Questions? regolo.ai/contact or chat with us on Discord