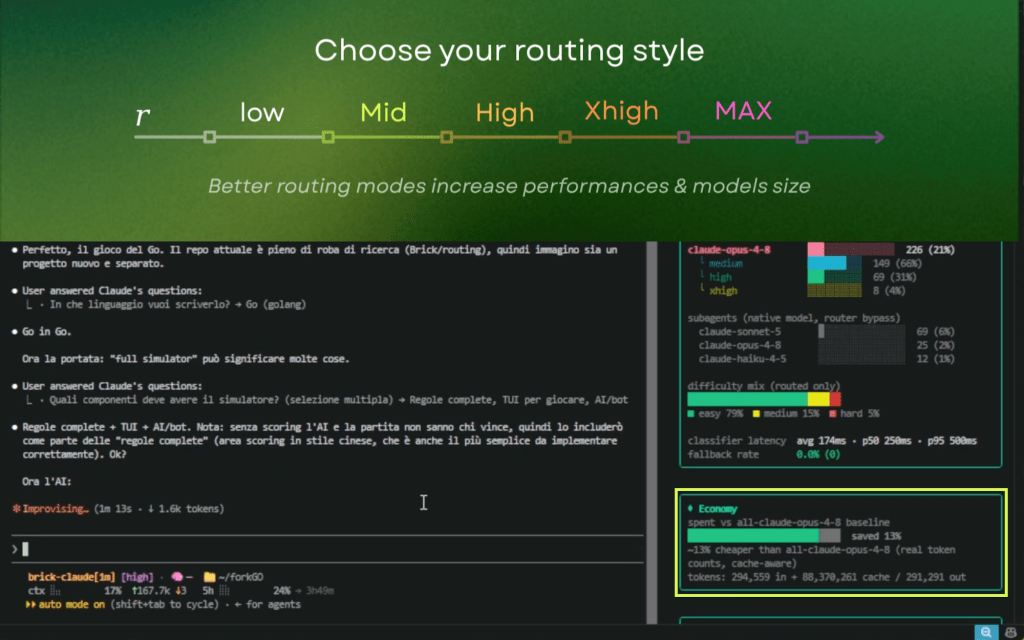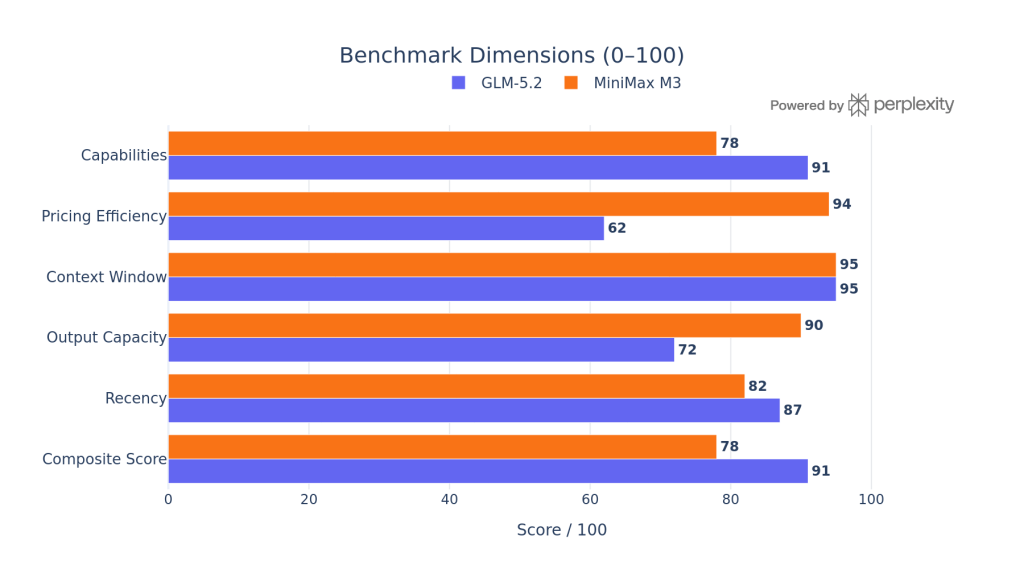
Case Studies & Community Stories
5 min read
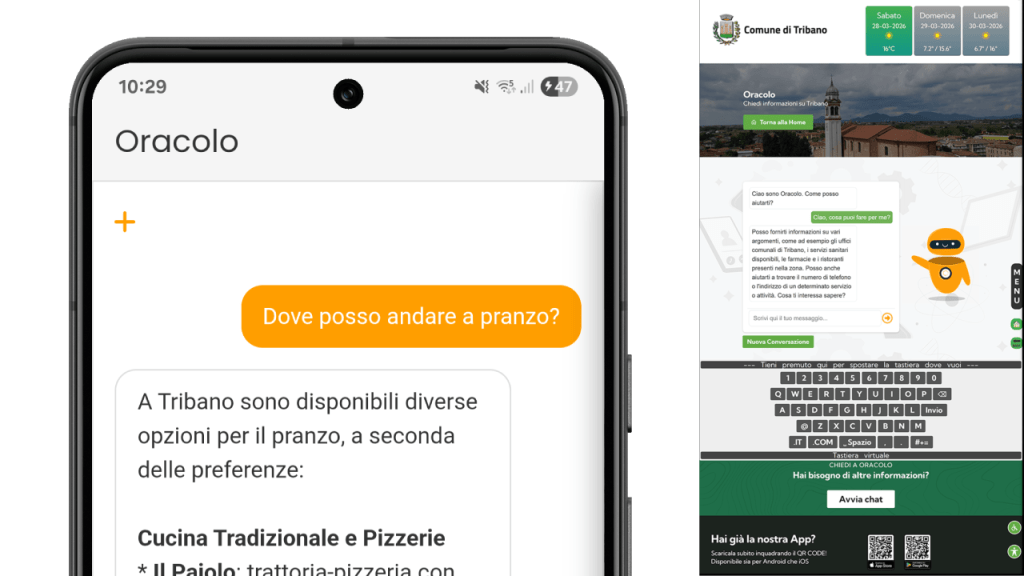
When research meets artificial intelligence: a bachelor’s thesis chooses Regolo to develop a chatbot for citizens
A university thesis explores the development of Oracolo, an AI assistant based on Regolo and RAG technology to improve access to public information.
Chiara Passarelli
Read article