
Open-source / open-weight models are no longer “second tier”: GLM-5.1 and Gemma 4 compete with or surpass closed LLMs on coding and reasoning benchmarks, while Qwen 3.5 offers multimodal and agentic features. Combined with local and decentralized inference (from mini PCs to P2P meshes), this gives a credible path to escape closed US-centric platforms while keeping data closer to home.
Why people want to escape closed providers
Teams are increasingly worried about data control, unpredictable pricing, and unilateral policy changes by closed providers. Open-weight models let us self-host or use European inference providers while keeping weights inspectable and licenses explicit (often MIT or Apache 2.0, with broad commercial rights).
For EU startups and enterprises, this aligns with GDPR and AI Act requirements on data residency, documentation, and vendor choice. Instead of streaming sensitive prompts to a US black-box, they can run or consume open models via providers like Regolo.ai, which runs in Italy with zero data retention and EU data sovereignty guarantees.
[ Grafico uso / costi ]
Qwen 3.5, GLM-5.1, Gemma 4: what’s new?
Qwen 3.5 is a family of open-weight LLMs from Alibaba with strong multilingual support, unified vision–language capabilities, long context (up to around 262K tokens in some variants), and an associated open agent framework. It includes sizes from sub‑1B to very large MoE models, covering both local deployment and high-end server inference.
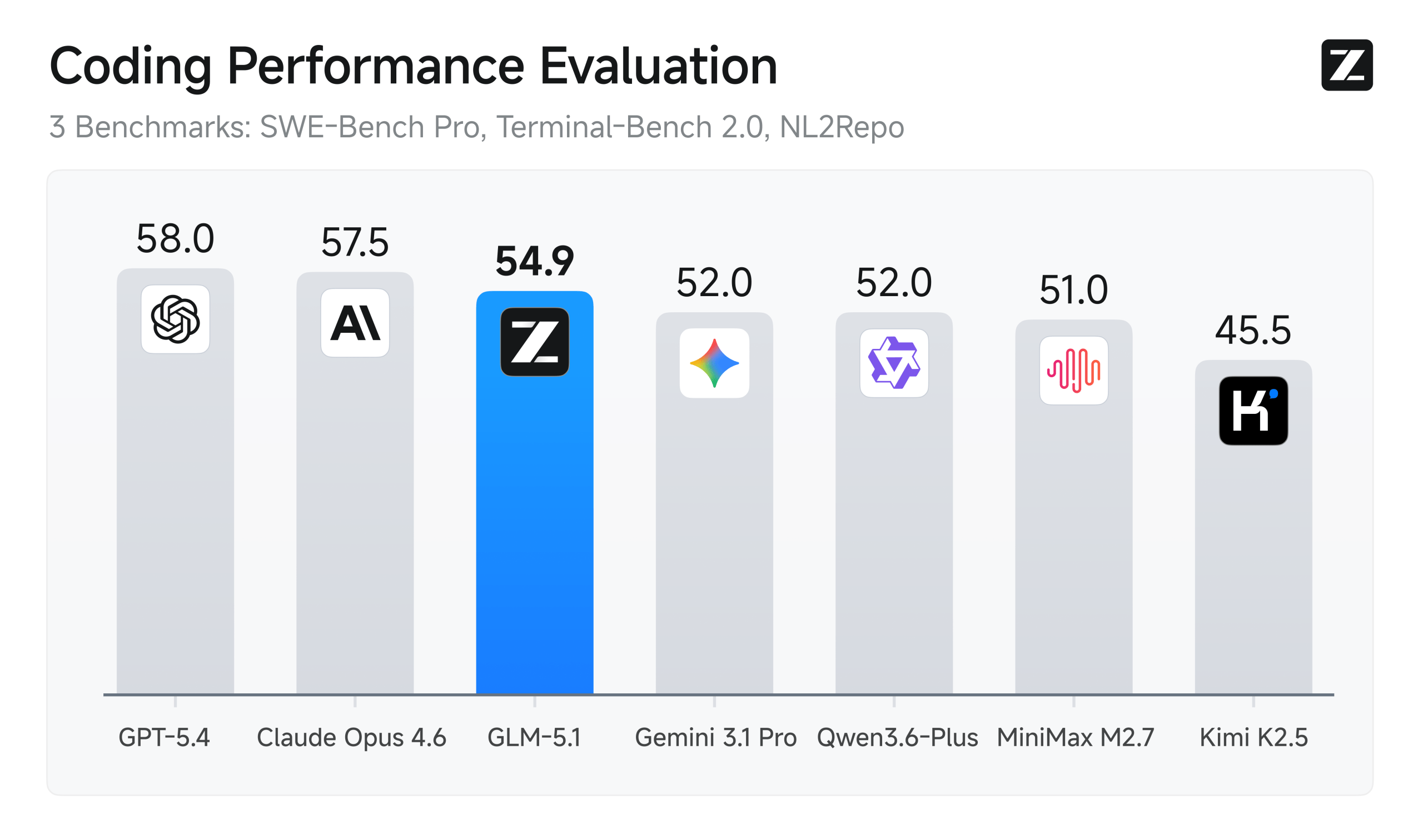
GLM-5.1 from Zhipu AI is a large MoE model designed for long-horizon reasoning and coding, reportedly scoring above 95% on some math benchmarks and competing strongly with leading closed models. Gemma 4 from Google DeepMind is a family of efficient models (2.3B–31B) with dense and MoE variants, Apache 2.0 license, and strong performance-per-parameter, especially the 31B dense model that outperforms much larger rivals.
| Category / Benchmark | Gemma-4-31B (Google) | GLM-5.1 (zai-org) | Notes / Apparent Winner |
|---|---|---|---|
| Parameters | 30.7B (dense) | 754B (MoE, ~40B active) | Gemma far more efficient |
| Context Length | 256K tokens | Long-horizon optimized (hundreds of turns) | Tie (GLM built for extreme sessions) |
| Native Function Calling / Tool Use | Yes (native + JSON mode + <think> reasoning) | Yes (core design, fully autonomous iteration) | Both excellent |
| τ2-bench (Agentic tool use – Retail) | 86.4% | Not reported | Gemma dominates |
| τ³-Bench (Multi-turn Tool / Agent) | Not reported | 70.6% | GLM |
| SWE-Bench Pro (Real GitHub coding agent) | Not reported | 58.4% (global SOTA open + closed) | GLM |
| Terminal-Bench 2.0 (Real terminal tasks) | Not reported | 63.5% | GLM |
| Tool-Decathlon (Multi-domain tool use) | Not reported | 40.7% | GLM |
| BrowseComp (Web navigation + context) | Not reported | 68.0% (79.3% with context management) | GLM |
| CyberGym (Cybersecurity simulation) | Not reported | 68.7% | GLM |
| NL2Repo (NL → full repo generation) | Not reported | 42.7% | GLM |
| HLE (with tools/search) | 26.5% (with search) | 52.3% | GLM |
| LiveCodeBench v6 (Agentic coding) | 80.0% | Not reported | Gemma |
| GPQA Diamond (Scientific reasoning, useful for agents) | 84.3% | 86.2% | Near tie |
Key Takeaways for Agentic Use
GLM-5.1 → Purpose-built for long-horizon autonomous agents. Dominates real-world complex benchmarks (SWE-Bench Pro, Terminal-Bench, BrowseComp, etc.) that require hundreds or thousands of tool calls and extended autonomy. The go-to model when building true software agents or long-running autonomous systems.
Gemma-4-31B → Excels at clean, fast tool use (τ2-bench 86.4%). Perfect for lightweight, local/edge agents, multimodal tasks, and quick reasoning. Easier to deploy locally and very strong on coding.
Open models on Data center privacy by design
We focus on GPU inference for open models, hosted entirely in european data centers with GDPR-compliant zero data retention. Instead of asking every team to manage their own GPU cluster for Qwen, Gemma, or GLM, we provide an API layer so you can consume these capabilities as a service, while keeping data in Europe and out of closed training pipelines.
In our page Models you can use all Core models in few seconds just signing into the platform and you’ll have a scalable and production ready infrastracture managed.
This gives a middle ground between fully local self-hosting and hyperscaler APIs. You keep the benefits of open weights (auditability, portability, license clarity) while offloading the hardest parts of GPU management, scaling, and observability. For European startups, this can significantly reduce both infrastructure complexity and regulatory friction compared with sending traffic to non-EU clouds.
FAQ
Are Qwen 3.5, GLM-5.1, and Gemma 4 truly competitive with closed LLMs?
Benchmarks and community analysis show these models matching or exceeding many closed models on coding, math, and reasoning in 2026. On some tasks, open models are now ahead.
What licenses do these open models use?
GLM-5.1 is typically MIT-licensed, while Gemma 4 uses Apache 2.0, both suitable for commercial use with relatively few restrictions. Qwen 3.5 is released as open-weight; details depend on specific variants and should be checked in the official repo.
Is decentralized inference production-ready?
Projects like mesh-LLM and Bittensor are promising but still early and experimental for many production workloads. Most teams today prefer either self-hosting or using managed open-model providers with clear SLAs.
How does this help with EU AI Act and GDPR?
Using open models on EU-hosted infrastructure with zero retention simplifies documentation, reduces cross-border transfer issues, and keeps training control with you. You still need to manage risk classification and impact assessments, but data flows become easier to justify.
Can I still use closed models for some tasks?
Yes. A common pattern is hybrid: open models for most workloads and a few closed APIs for very specialized capabilities, with routing logic sitting in your app. Open-weight + Regolo.ai becomes the default, with closed APIs as exceptions rather than the core.
🚀 Start your free 30-day trial at regolo.ai and deploy LLMs with complete privacy by design.
👉 Talk with our Engineers or Start your 30 days free →
- Discord – Share your thoughts
- GitHub Repo – Code of blog articles ready to start
- Follow Us on X @regolo_ai
- Open discussion on our Subreddit Community
Built with ❤️ by the Regolo team. Questions? regolo.ai/contact or chat with us on Discord