Benchmarks & Cost Optimization
3 min read
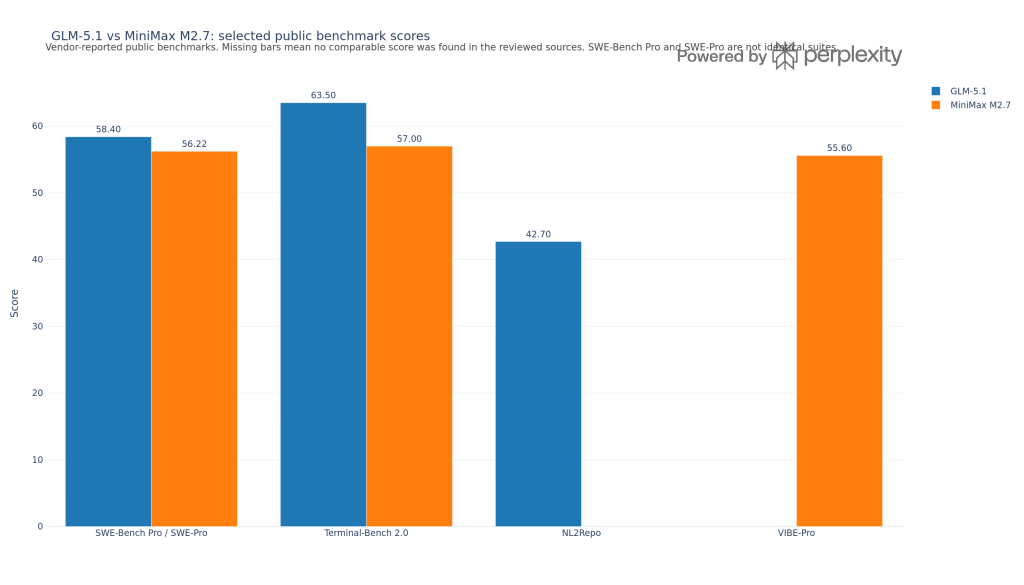
GLM-5.1 vs MiniMax M2.7: which open model looks better on public benchmarks?
Based on the public benchmarks we reviewed, GLM-5.1 has the stronger benchmark profile for long-horizon coding and agentic work, while MiniMax M2.7 looks cheaper…
Alex Genovese
Read article










