Based on the public benchmarks we reviewed, GLM-5.1 has the stronger benchmark profile for long-horizon coding and agentic work, while MiniMax M2.7 looks cheaper to run and may be the better fit when throughput and budget matter more than absolute score.
We would frame it this way: choose GLM-5.1 when benchmark-leading engineering performance is the priority, and consider MiniMax M2.7 when cost efficiency and fast operational execution matter more.
With this benchmark we’re showing which model can be a best fit for you daily work and how you can get the best from it.
Below is the English matrix, built only from the benchmark, pricing, context-window, and license evidence already collected; it shows workload fit, not audited market share. The strongest pattern in the current data is that GLM-5.1 leads on aggregate coding and agentic benchmarks, while MiniMax M2.7 is materially cheaper and has published speed data.
| Sector | Operational task | Best fit | Why | Evidence strength |
|---|---|---|---|---|
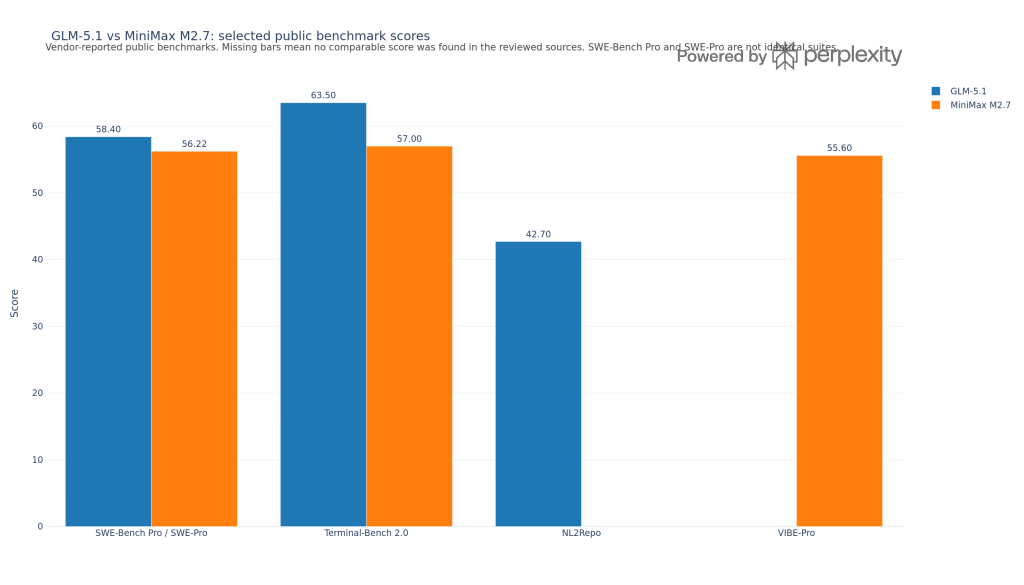
| Software engineering platforms | Large-codebase debugging, patch generation, repo-level reasoning | GLM-5.1 | GLM-5.1 scores higher on aggregate coding, 60.9 vs 53.7, and higher on agentic, 65.3 vs 57; it also reports 58.4 on SWE-Bench Pro. | High, because the evidence is directly benchmark-based. |
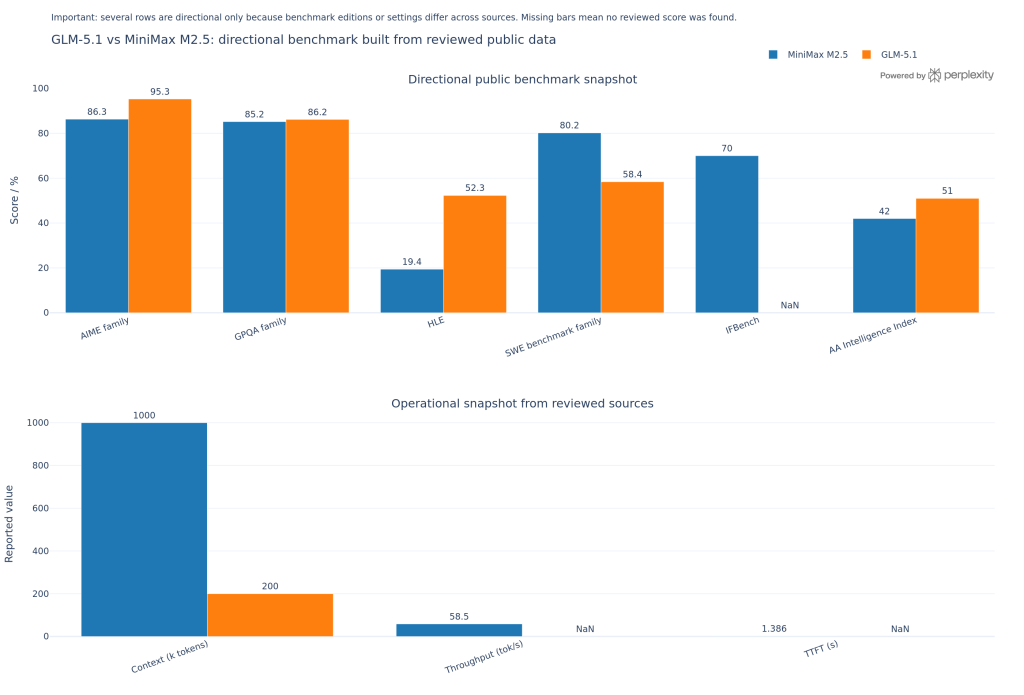
| Software engineering platforms | Cost-controlled CI fixes, repetitive code edits, batch transformations | MiniMax M2.7 | MiniMax M2.7 is priced lower at 0.3 input and 1.2 output dollars per 1M tokens versus 1.4 and 4.4 for GLM-5.1, and it has published speed data of 45 tok/s with 2.53s TTFT. | High for cost and speed, medium for end-task quality. |
| Agentic development tools | Multi-step coding agents and tool-using workflows | GLM-5.1 | GLM-5.1 leads on the aggregate agentic score, and the GLM-5 family also publishes strong Terminal-Bench 2.0 numbers at 56.2 or 60.7 depending on the verified setup. reddit+1 | High for direction, medium for exact task mapping. |
| Enterprise AI products | Commercial product integration with fewer licensing constraints | GLM-5.1 | GLM-5.1 is listed with an MIT license, while MiniMax M2.7 is listed with a non-commercial license. | High, because this is a direct product constraint. |
| Enterprise internal copilots | Long-context internal assistants over large document sets | GLM-5.1 for commercial use; near tie technically | Context windows are close at 200k for GLM-5.1 and 205k for MiniMax M2.7, so the practical separator is license rather than context length. | High for context and license, low for retrieval quality. |
| Multilingual engineering teams | Cross-language software maintenance and global dev support | Provisional tie, slight edge to whichever benchmark matches your stack | MiniMax reports 76.5 on SWE Multilingual, while GLM-5 reports 73.3 on SWE-bench Multilingual, but the published benchmarks are not perfectly aligned as one-to-one equivalents. | Medium, because the multilingual scores come from different benchmark labels. |
| Research and browsing agents | Web-style research, browse-heavy agent loops, information gathering | GLM-5.1 / GLM-5 family | GLM-5 publishes 62.0 on BrowseComp, while no comparable MiniMax browsing metric appears in the gathered set. | Medium, because only one side has a directly comparable public metric. |
| Cybersecurity research | Security testing assistants and cyber task automation | GLM-5.1 / GLM-5 family | GLM-5 publishes 43.2 on CyberGym, while no equivalent MiniMax cyber benchmark appears in the gathered set. | Medium, because the public evidence is one-sided. |
For teams optimizing for raw coding quality, agent loops, and benchmark-facing performance, GLM-5.1 is the safer default based on the current public numbers. Instead for teams optimizing for token cost, quick turnaround, and high-volume engineering automation, MiniMax M2.7 looks stronger on operational efficiency.
FAQ
Is GLM-5.1 better than MiniMax M2.7?
On the public benchmark evidence we reviewed, yes for aggregate coding and agentic quality, but not necessarily on cost efficiency or operational speed.
Is MiniMax M2.7 still competitive?
Yes. Its reported results on SWE-Pro, Terminal Bench 2, and VIBE-Pro show that it remains close enough to matter, especially when price and throughput are part of the decision.
Which one is easier to use commercially?
GLM-5.1 appears easier for commercial adoption because Artificial Analysis lists it under MIT, while MiniMax M2.7 is listed under a non-commercial license.
What should we do before choosing?
We should run a small internal eval on the exact workflow we care about, using the same prompts, tools, and budget limits on both models through regolo
🚀 Start your free 30-day trial at regolo.ai and deploy LLMs with complete privacy by design.
👉 Talk with our Engineers or Start your 30 days free →
- Discord – Share your thoughts
- GitHub Repo – Code of blog articles ready to start
- Follow Us on X @regolo_ai
- Open discussion on our Subreddit Community
Built with ❤️ by the Regolo team. Questions? regolo.ai/contact or chat with us on Discord