
DFlash is an effective speculative decoding algorithm designed to accelerate Large Language Model (LLM) inference without altering the core weights of your main verifier model. It uses a lightweight, diffusion-style draft model that predicts whole blocks of tokens in parallel, which the target model then verifies in a single pass. This tutorial walks through what DFlash is, how it compares to alternative speculative decoding methods, and how to train and serve a DFlash speculator utilizing the vllm-project/speculators library on modern GPUs.
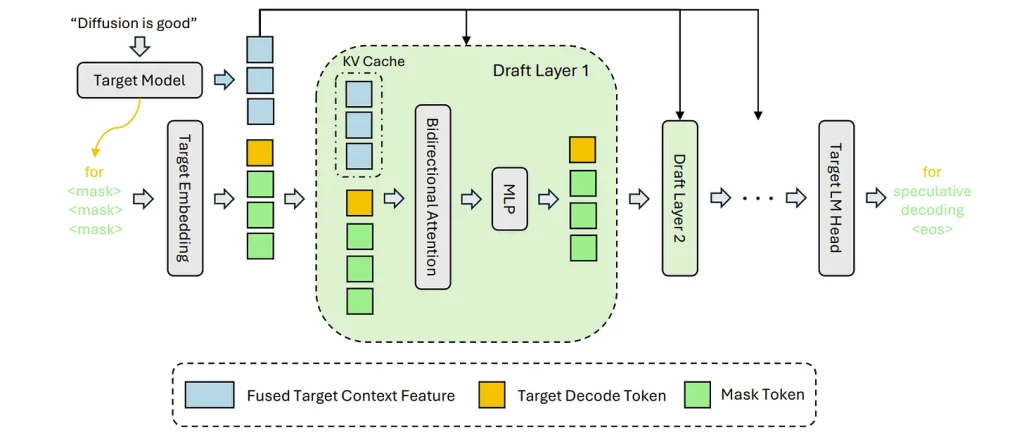
Illustration from the paper
What DFlash Speculative Decoding Is
DFlash is a speculative decoding method where a small draft model (speculator) proposes a block of future tokens, and a larger verifier model (the main LLM) accepts or rejects them. Instead of generating tokens one by one autoregressively, the draft model predicts several tokens simultaneously, and the verifier checks them in a single parallel step.
The fundamental concept behind DFlash is block diffusion. It utilizes a transformer architecture configured with a non-causal (bidirectional) attention mask. This allows the draft model to attend to all positions within a speculative block concurrently. Rather than querying a sequence of causal autoregressive steps, DFlash takes hidden states from the verifier model and processes special mask tokens to produce logits for the entire block in a single forward pass.
How DFlash Differs from MTP and Eagle-Style Drafting
- Multi-Token Prediction (MTP): Adds dedicated, sequential projection heads directly on top of the main LLM to predict future tokens. MTP often requires co-training or modifying the base model itself.
- Eagle-Style (e.g., EAGLE-3): Uses a separate, smaller autoregressive (AR) draft model. While powerful, it still decodes sequentially, resulting in higher inter-token latency during drafting.
- DFlash: Deploys a separate diffusion-like draft model with bidirectional attention. Draft tokens are generated in parallel in one pass. This parallelized block approach can produce larger throughput gains on synchronous, high-throughput pipelines once tuned.
Operational Mechanics: The Speculators Architecture
Inside the vLLM speculators framework, the DFlash pipeline operates in four primary stages:
- Hidden State Extraction: The verifier model processes the prompt context and yields intermediate hidden states.
- Anchor Points and Masking: DFlash identifies anchor points in the sequence and appends mask tokens for the block locations to be predicted.
- Parallel Drafting: Combined context features and mask embeddings are routed through multiple speculator draft layers (typically 5 layers) with bidirectional attention, generating logits for the whole block.
- Verification: The verifier validates the block in a single pass, selecting the longest matching prefix and discarding mismatched tokens.
Hardware and Resource Allocation Considerations
Because DFlash training is typically online (hidden states are extracted on-the-fly from a running vLLM server to train the speculator), you must carefully isolate your GPU resources to avoid Out of Memory (OOM) exceptions.
If you are serving a medium-to-large model (such as Qwen 27B or Gemma 4 31B), you should divide your GPU cluster:
- Verifier (vLLM Server) GPUs: Isolated for hosting the main model and streaming hidden states.
- Training GPUs: Dedicated exclusively to running the PyTorch/torchrun speculator training loop.
For a 27B–30B model, starting with at least 4 datacenter-grade GPUs (such as H100s) is recommended: 2 GPUs dedicated to vLLM (Tensor Parallelism = 2) and 2 GPUs dedicated to the DFlash training process.
Step-by-Step Guide: Training a DFlash Speculator
We will use the official speculators scripts to execute data preprocessing, online verification serving, and speculator training.
Step 1: Preprocess and Tokenize the Dataset
First, preprocess the raw dataset (such as sharegpt or ultrachat) to format it for token extraction. This computes token frequencies and prepares Arrow datasets on disk.
# Executed in your speculators virtual environment
python scripts/prepare_data.py \
--model Qwen/Qwen3-8B \
--data sharegpt \
--output ./output/dflash_qwen3_8b_sharegpt \
--seq-length 8192Code language: Bash (bash)The script scripts/prepare_data.py contains the following structural configuration:
import argparse
def main():
parser = argparse.ArgumentParser(description="Prepare data for Speculators training")
parser.add_argument("--model", type=str, required=True)
parser.add_argument("--data", type=str, required=True)
parser.add_argument("--output", type=str, required=True)
parser.add_argument("--seq-length", type=int, default=8192)
args = parser.parse_args()
print(f"STUB: Preprocessing data from '{args.data}' for model '{args.model}'...")
print(f"STUB: Outputs will be saved to '{args.output}'")
print("NOTE: For training, please install the official vllm-project/speculators library and use their scripts.")
if __name__ == "__main__":
main()Code language: Python (python)Step 2: Launch the Hidden States Server
The speculator does not read raw texts directly during online training. It inputs intermediate hidden states from the target model.
To enable this extraction, run vLLM via the Speculators wrapper script scripts/launch_vllm.py. For DFlash, you must explicitly specify the intermediate layers to extract hidden states from using –target-layer-ids.
# Isolate to GPUs 0 and 1
CUDA_VISIBLE_DEVICES=0,1 python scripts/launch_vllm.py Qwen/Qwen3-8B \
--target-layer-ids 2 10 18 26 34 \
-- \
--port 8000 \
--gpu-memory-utilization 0.9 \
--tensor-parallel-size 1 \
--data-parallel-size 2Code language: Bash (bash)Note: The — separator routes any subsequent flags directly to the underlying vLLM engine.
The helper script scripts/launch_vllm.py structure:
import argparse
def main():
parser = argparse.ArgumentParser(description="Launch vLLM server configured for hidden states extraction")
parser.add_argument("model", type=str)
parser.add_argument("--target-layer-ids", nargs="+", required=True)
args, vllm_args = parser.parse_known_args()
print(f"STUB: Launching vLLM wrapper for model: {args.model}")
print(f"STUB: Extracting target layer IDs: {args.target_layer_ids}")
print(f"STUB: Raw arguments passed directly to vLLM: {vllm_args}")
print("NOTE: Replace this placeholder with the official implementation from vllm-project/speculators.")
if __name__ == "__main__":
main()Code language: Python (python)Step 3: Run the Online DFlash Training
Once the vLLM server is running, launch the training script in a separate terminal or background process. We use torchrun to train across our remaining GPUs (GPUs 2 and 3).
# Isolate to GPUs 2 and 3
CUDA_VISIBLE_DEVICES=2,3 torchrun \
--standalone \
--nproc_per_node=2 \
scripts/train.py \
--verifier-name-or-path Qwen/Qwen3-8B \
--speculator-type dflash \
--num-layers 5 \
--data-path ./output/dflash_qwen3_8b_sharegpt \
--vllm-endpoint http://localhost:8000/v1 \
--save-path ./checkpoints/dflash_speculator \
--epochs 3 \
--lr 0.0006 \
--total-seq-len 8192 \
--on-missing generate \
--on-generate delete \
--seed 42 \
--draft-vocab-size 32000 \
--target-layer-ids 2 10 18 26 34 \
--scheduler-type cosine \
--max-anchors 3072Code language: Bash (bash)The script scripts/train.py structure:
import argparse
def main():
parser = argparse.ArgumentParser(description="Train speculative decoding draft models")
parser.add_argument("--verifier-name-or-path", type=str, required=True)
parser.add_argument("--speculator-type", type=str, required=True)
parser.add_argument("--target-layer-ids", nargs="+", required=True)
parser.add_argument("--data-path", type=str, required=True)
parser.add_argument("--vllm-endpoint", type=str, required=True)
parser.add_argument("--save-path", type=str, required=True)
parser.add_argument("--max-anchors", type=int, default=3072)
parser.add_argument("--num-layers", type=int, default=5)
args, _ = parser.parse_known_args()
print(f"STUB: Starting online {args.speculator_type} training...")
print(f"STUB: Connecting to vLLM endpoint: {args.vllm_endpoint}")
print(f"STUB: Saving checkpoints to: {args.save_path}")
print("NOTE: Replace this placeholder with the official implementation from vllm-project/speculators.")
if __name__ == "__main__":
main()Code language: Python (python)Key Parameters Explained:
- –speculator-type dflash: Instructs the trainer to initialize a DFlash architecture instead of an Eagle model.
- –num-layers 5: Specifies the draft layers (DFlash generally employs a 5-layer configuration compared to Eagle-3’s 1-layer setup).
- –target-layer-ids: Must match the exact layers passed to the vLLM server during Step 2.
- –max-anchors 3072: Adjusts the anchoring density for the block diffusion mechanism.
Running DFlash with vLLM
After training, you can serve your base verifier model accelerated by your new DFlash speculator checkpoint. vLLM natively supports the DFlash speculator via the speculative config arguments:
vllm serve Qwen/Qwen3-8B \
--tensor-parallel-size 2 \
--max-model-len 16384 \
--speculative-config '{
"method": "dflash",
"model": "./checkpoints/dflash_speculator",
"num_speculative_tokens": 15
}' \
--attention-backend flash_attn \
--dtype bfloat16Code language: Bash (bash)or deploy the model in Custom Models on Regolo infrastructure.
Speculative Decoding Method Comparison
| Method | Drafting Architecture | Separate Model? | Speedup Range (Typical) | Best Use Case |
| MTP Heads | Linear heads on top of LLM | No (Built into main) | 1.5–2.0× | When you can fine-tune or pre-train the main model weights |
| Eagle-Style | Small Autoregressive Model | Yes | 2.0–3.0× | Diverse workloads where low training overhead is desired |
| DFlash | Non-causal Block Diffusion | Yes | 3.0–6.0× | High-throughput synchronous APIs where low latency is critical |
FAQ
What is DFlash in LLM inference?
DFlash is a speculative decoding algorithm where a lightweight diffusion-style draft model predicts blocks of future tokens that a larger verifier model then accepts or rejects in parallel.
How much faster is DFlash compared to normal decoding?
Reported speedups on modern GPUs range from about 3× to 5× for synchronous workloads, with some setups reaching higher gains depending on model, hardware, and anchor tuning.
Do I need to fine-tune my main LLM to use DFlash?
No, DFlash uses a separate speculator model, so the verifier checkpoint (your main LLM) can remain unchanged.
Can DFlash hurt model quality?
If the draft model is poorly trained or anchors are too aggressive, speculative decoding can slightly degrade task accuracy; proper training and evaluation largely mitigate this.
Is DFlash compatible with quantized models?
The DFlash paper reports that it works with quantized verifiers, including certain quantization schemes like ParoQuant, as long as the inference stack supports them.
Github
You can download the codes on our Github repo, just download and follow the README steps. If need help you can always reach out our team on Discord 🤙
Start your free 30-day trial at regolo.ai and deploy LLMs with complete privacy by design.
👉 Talk with our Engineers or Start your 30 days free →
- Discord – Share your thoughts
- GitHub Repo – Code of blog articles ready to start
- Follow Us on X @regolo_ai
- Open discussion on our Subreddit Community
Built with ❤️ by the Regolo team. Questions? regolo.ai/contact or chat with us on Discord