Most multi‑agent systems in production still “just pass prompts around”, which is exactly what breaks as soon as you add enterprise clients, ticket data, and compliance requirements. If your team is building an AI support copilot or a multi‑agent RAG assistant for customers, you need a communication protocol that is auditable, enforceable, and decoupled from any single LLM vendor.
This article uses a concrete use case—a multi‑agent customer support copilot backed by RAG—to show how to design a governance‑ready communication protocol that you can implement with HTTP and JSON today.
Customer support and knowledge assistants are among the most deployed and funded GenAI use cases in enterprises: AI agents that resolve tickets end‑to‑end, backed by RAG over internal knowledge bases. Agencies and service providers that run these systems for multiple enterprise customers sit right in the blast radius of any data leak, access overreach, or missing audit trail.
If your agents are just calling each other with free‑form prompts and ad‑hoc JSON, you have no stable contract, no robust audit trail, and no enforceable policy layer. That makes it hard to debug issues, impossible to prove compliance, and painful to migrate to a European, privacy‑first inference provider when a client demands EU‑only processing.
Why “just calling agents” doesn’t scale
Many teams start multi-agent systems like this: an orchestrator calls a model with a prompt that describes other agents; messages are just raw text or ad-hoc JSON blobs passed around. It works for prototypes, but three issues appear as soon as you add scale and compliance:
- No stable contract. Prompts change, JSON structures drift, and downstream agents break silently.
- No robust audit trail. You might have LLM trace logs, but no canonical record of “who asked what, under which policy, and with which data sensitivity level”.
- No enforceable policy. Permissions live in prompts instead of in a protocol and enforcement layer, so agents can exfiltrate or overreach with a single prompt mistake.
In an enterprise environment, this is not just messy; it’s a governance risk. Audit teams need to reconstruct why a system took a action and which components were involved.
Use Case: multi‑agent RAG for customer support
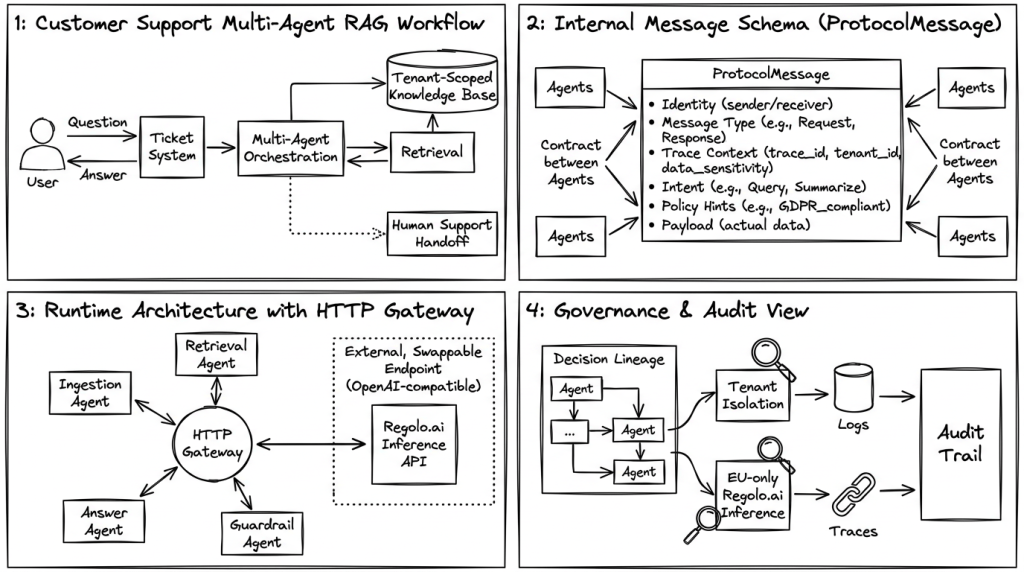
Imagine a structured agency with several enterprise customers. You are building a support copilot that:
- reads tickets from the client’s helpdesk;
- retrieves relevant docs from their knowledge base;
- drafts answers;
- routes edge cases to human agents with full reasoning and provenance.
Multi‑agent is not a buzzword here; it reflects how you model responsibilities:
- Ingestion agent – normalizes tickets and classifies intent/priority.
- Retrieval agent – queries RAG over client‑specific knowledge.
- Answer agent – drafts responses, constrained by tone and policy.
- Guardrail/evaluator agent – checks for hallucinations, PII issues, and policy violations before anything leaves your environment.
This is similar to what many teams implement under labels like “autonomous customer support assistant” and “multi‑agent RAG pipelines for customer support search & KB chat”.
Without a protocol, these agents just sling untyped blobs around. Once you need to prove to a bank’s DPO that “this answer never saw confidential tickets from another tenant, and that no agent could call production APIs”, you are in trouble.
The minimum protocol: message schema you can actually enforce
A governance‑ready protocol is simply a shared message schema that every agent and orchestrator must respect. You do not need a new standard, but you do need to stop treating messages as arbitrary JSON.
For the customer support copilot, you can start with a message shape like this:
- reads tickets from the client’s helpdesk;
- retrieves relevant docs from their knowledge base;
- drafts answers;
- routes edge cases to human agents with full reasoning and provenance.
Multi‑agent reflect how you model responsibilities:
- Ingestion agent – normalizes tickets and classifies intent/priority.
- Retrieval agent – queries RAG over client‑specific knowledge.
- Answer agent – drafts responses, constrained by tone and policy.
- Guardrail/evaluator agent – checks for hallucinations, PII issues, and policy violations before anything leaves your environment.
This is similar to what many teams implement under labels like “autonomous customer support assistant” and “multi‑agent RAG pipelines for customer support search & KB chat”.
Without a protocol, these agents just sling untyped blobs around. Once you need to prove to a bank’s DPO that “this answer never saw confidential tickets from another tenant, and that no agent could call production APIs”, you are in trouble.
Configure Regolo API as inference provider
We expose an OpenAI‑compatible API at an HTTPS endpoint (for example https://api.regolo.ai/v1), and a /models endpoint to inspect available models. For the support copilot, you’ll usually pick a general‑purpose chat model from the Core Models catalog such as Llama-3.3-70B-Instruct or another high‑quality instruction‑tuned model.
// src/config/regolo.ts
export const REGOLO_BASE_URL =
process.env.REGOLO_BASE_URL ?? 'https://api.regolo.ai/v1';
export const REGOLO_API_KEY =
process.env.REGOLO_API_KEY ?? ''; // inject via env/secret manager
// Choose a default model from Regolo's catalog.
// For a support copilot, a large instruct model is a good default.
// See https://docs.regolo.ai and the /models endpoint for current options. [web:20][web:27]
export const REGOLO_DEFAULT_CHAT_MODEL =
process.env.REGOLO_DEFAULT_CHAT_MODEL ?? 'Llama-3.3-70B-Instruct';Code language: JavaScript (javascript)Optional: a small script to list models from Regolo so your team can pick/configure them without guessing.
// scripts/list-regolo-models.tsimport fetch from 'node-fetch';
import { REGOLO_BASE_URL, REGOLO_API_KEY } from '../src/config/regolo';
async function listModels() {
const res = await fetch(`${REGOLO_BASE_URL.replace(/\/v1$/, '')}/models`, {
headers: {
'Authorization': `Bearer ${REGOLO_API_KEY}`
}
});
if (!res.ok) {
console.error('Failed to fetch Regolo models', res.status, await res.text());
process.exit(1);
}
const models = await res.json();
console.log(JSON.stringify(models, null, 2));
}
listModels().catch(console.error);Code language: JavaScript (javascript)This keeps the protocol layer independent from any concrete model name while still grounding the tutorial on Regolo.
Update the answer agent to call Regolo’s OpenAI‑compatible API
We now plug Regolo into the answer agent with minimal changes: only base URL, API key, and model name differ from a generic OpenAI setup.
// src/agents/answer.ts
import { ProtocolMessage } from './types';
import crypto from 'crypto';
import fetch from 'node-fetch';
import {
REGOLO_BASE_URL,
REGOLO_API_KEY,
REGOLO_DEFAULT_CHAT_MODEL
} from '../config/regolo';
const GATEWAY_URL =
process.env.GATEWAY_URL ?? 'http://gateway:8080/agent-message';
// Thin wrapper over Regolo's OpenAI-compatible chat completions API. [web:19][web:20]
async function callRegoloChatCompletion(prompt: string, maxTokens: number) {
const res = await fetch(`${REGOLO_BASE_URL}/chat/completions`, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${REGOLO_API_KEY}`
},
body: JSON.stringify({
model: REGOLO_DEFAULT_CHAT_MODEL,
messages: [
{
role: 'system',
content:
'You are a B2B support agent. Use only provided knowledge snippets. If unsure, escalate instead of inventing an answer.'
},
{ role: 'user', content: prompt }
],
max_tokens: maxTokens,
temperature: 0.2
})
});
if (!res.ok) {
const text = await res.text();
throw new Error(`Regolo inference error: ${res.status} ${text}`);
}
const json = await res.json();
const content = json.choices?.[0]?.message?.content ?? '';
return content;
}
export async function handleAgentMessage(msg: ProtocolMessage<any>) {
if (msg.intent !== 'DRAFT_ANSWER_V1' || msg.type !== 'TASK_RESULT') {
return;
}
const { ticket, kb_snippets } = msg.payload;
const kbText = kb_snippets
.map((s: any) => `Doc ${s.id} (score ${s.score}): ${s.snippet}`)
.join('\n\n');
const prompt = [
`Ticket subject: ${ticket.subject}`,
`Ticket body: ${ticket.body}`,
'',
'Use ONLY the information below to draft a response. If the answer is not clearly covered, say that you need to escalate to a human agent.',
'',
kbText
].join('\n');
const maxTokens = msg.policy.max_cost_tokens ?? 1500;
const draft = await callRegoloChatCompletion(prompt, maxTokens);
const response: ProtocolMessage<any> = {
id: crypto.randomUUID(),
timestamp: new Date().toISOString(),
from: {
agent_id: 'answer@support-bot',
agent_role: 'answer',
capabilities: ['llm.generate']
},
to: {
agent_id: 'guardrail@support-bot',
agent_role: 'guardrail'
},
type: 'TASK_RESULT',
intent: 'EVALUATE_AND_APPROVE_ANSWER_V1',
schema_version: msg.schema_version,
trace: msg.trace,
policy: {
max_cost_tokens: 1000,
max_duration_ms: 5000,
allowed_tools: ['llm.moderate'],
allowed_data_domains: msg.policy.allowed_data_domains
},
payload: {
ticket,
kb_snippets,
draft_answer: draft
}
};
await fetch(GATEWAY_URL, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify(response)
});
}Code language: JavaScript (javascript)If you already use OpenAI SDKs, you can point them at Regolo by changing only baseURL and the key, as Regolo is explicitly built on the OpenAI API contract. Here the link to official docs for Javascript.
Model choice sits in REGOLO_DEFAULT_CHAT_MODEL, so you can A/B test different models (e.g. Llama-3.3-70B-Instruct, qwen3.5-9b, etc.) for quality/cost without touching the protocol or agent logic.
Optional: use Regolo also for retrieval (embeddings / rerank)
Many teams push more work into the inference layer by using embeddings and rerankers from the same provider used for chat. Regolo exposes embeddings and rerank models over the same API, so you can keep the retrieval agent cleanly wired to it.
Example: compute embeddings in the retrieval agent and store them in your own vector DB:
// src/agents/retrieval-embeddings.ts
import fetch from 'node-fetch';
import { ProtocolMessage } from './types';
import {
REGOLO_BASE_URL,
REGOLO_API_KEY
} from '../config/regolo';
const EMBEDDINGS_MODEL =
process.env.REGOLO_EMBEDDINGS_MODEL ?? 'text-embedding-3-small'; // check catalog [web:27]
async function embedWithRegolo(input: string[]): Promise<number[][]> {
const res = await fetch(`${REGOLO_BASE_URL}/embeddings`, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${REGOLO_API_KEY}`
},
body: JSON.stringify({
model: EMBEDDINGS_MODEL,
input
})
});
if (!res.ok) {
throw new Error(`Regolo embeddings error: ${res.status} ${await res.text()}`);
}
const json = await res.json();
return json.data.map((d: any) => d.embedding);
}
export async function handleAgentMessage(msg: ProtocolMessage<any>) {
if (msg.intent !== 'RETRIEVE_KB_SNIPPETS_V1' || msg.type !== 'TASK_REQUEST') {
return;
}
const { tenant_id } = msg.trace;
const { subject, body } = msg.payload;
const query = `${subject}\n\n${body}`.slice(0, 2000);
const [queryEmbedding] = await embedWithRegolo([query]);
// ... use queryEmbedding with your vector DB in a tenant-scoped index
// produce TASK_RESULT as in the previous version
}Code language: JavaScript (javascript)This keeps all ML-ish work inside Regolo (chat + embeddings + optional rerankers) while your protocol and storage stay fully under your control.
What changes for governance and compliance when you use Regolo
From a governance angle, nothing in your protocol changes:
ProtocolMessagestill carriestenant_id,data_sensitivity, andpolicy_scopefor all internal traffic.- The gateway still logs everything internally and enforces which agents can call which tools or data domains.
What does change is:
- the inference endpoints now point to a European provider with zero data retention and EU data centers, which aligns better with GDPR and AI Act expectations for your enterprise clients.
- switchovers (e.g. moving only finance or healthcare tenants to stricter models / regions) become a configuration problem, not an architecture problem: you update
REGOLO_BASE_URL/ model names per tenant, and keep the protocol invariant.
For a structured agency with multiple enterprise customers, this is usually the cleanest way to satisfy client‑specific data residency and privacy requirements without fragmenting the codebase.
FAQ
Is this overkill for a single‑agent chatbot?
For a single agent with no sensitive data, probably yes. Once you touch multiple agents, multiple tenants, or regulated content (support tickets, KYC docs, internal policies), the protocol layer becomes cheap insurance.
Do I really need a gateway, or can agents call each other directly?
Agents can technically call each other directly, but you then scatter validation, auth, and policy across services. A simple gateway centralizes enforcement and observability with minimal overhead.
What about using a multi‑agent framework instead?
Frameworks are great for prototyping and internal tools, but their message formats and logs rarely align with your enterprise observability and security stack. Use them for exploration, then standardize production communication on your own protocol over HTTP or a bus.
How does this help with AI Act and GDPR?
A structured protocol makes data minimization, transparency, and accountability easier: you know which agent saw which data, under which policy scope, and you can show it. Combined with an EU, zero‑retention inference provider, this reduces regulatory friction.
Can I retrofit this onto an existing system?
Yes, but do it incrementally: introduce the message schema at the orchestrator boundary first, add the gateway, and progressively adapt each agent. Start with the highest‑risk use case (usually customer‑facing support or compliance workflows).
Start your free 30-day trial at regolo.ai and deploy LLMs with complete privacy by design.
👉 Talk with our Engineers or Start your 30 days free →
- Discord – Share your thoughts
- GitHub Repo – Code of blog articles ready to start
- Follow Us on X @regolo_ai
- Open discussion on our Subreddit Community
Built with ❤️ by the Regolo team. Questions? regolo.ai/contact or chat with us on Discord