Choosing between MiniMax and DeepSeek is not a single decision — it depends on which size tier you are operating in. This article organizes the comparison into two parameter-equivalent tiers: Tier 1 (~230–284B total parameters) and Tier 2 (~456B vs frontier reasoning). Within each tier, you will find verified benchmark data, pricing, context window, throughput, and a composite score to guide architecture decisions.
Why parameter equivalence matters
Comparing MiniMax-M2 (230B total, 10B active at inference) directly against DeepSeek-V4-Pro (1.6T total, 49B active) is not a fair benchmark — it is like comparing a GTX 4070 to an H200. The parameter count determines hardware requirements, cost envelope, and the baseline capability ceiling. The correct comparisons are:
- Tier 1 — mid-size efficiency: MiniMax-M2 / M2.7 (230B, 10B active) vs DeepSeek-V4-Flash (284B, 13B active)
- Tier 2 — frontier reasoning: MiniMax-M1 (456B, 45.9B active) vs DeepSeek-V4-Pro (1.6T, 49B active)
Both tiers are MIT-licensed and open-weight, meaning you can self-host on European infrastructure.
Tier 1 — ~230–284B: MiniMax-M2/M2.7 vs DeepSeek-V4-Flash
MiniMax-M2 launched on October 23, 2025 with 230B total parameters and 10B active per token. Its successor M2.7 was released March 17, 2026, maintaining the same weight footprint but trained with a self-improvement loop that pushed its Artificial Analysis Intelligence Index score to 50/100 — first among open-source models at that price point at release. DeepSeek-V4-Flash launched April 24, 2026 with 284B total / 13B active, inheriting the same 1M-token hybrid attention architecture as V4-Pro at a significantly reduced weight footprint.
Benchmark comparison
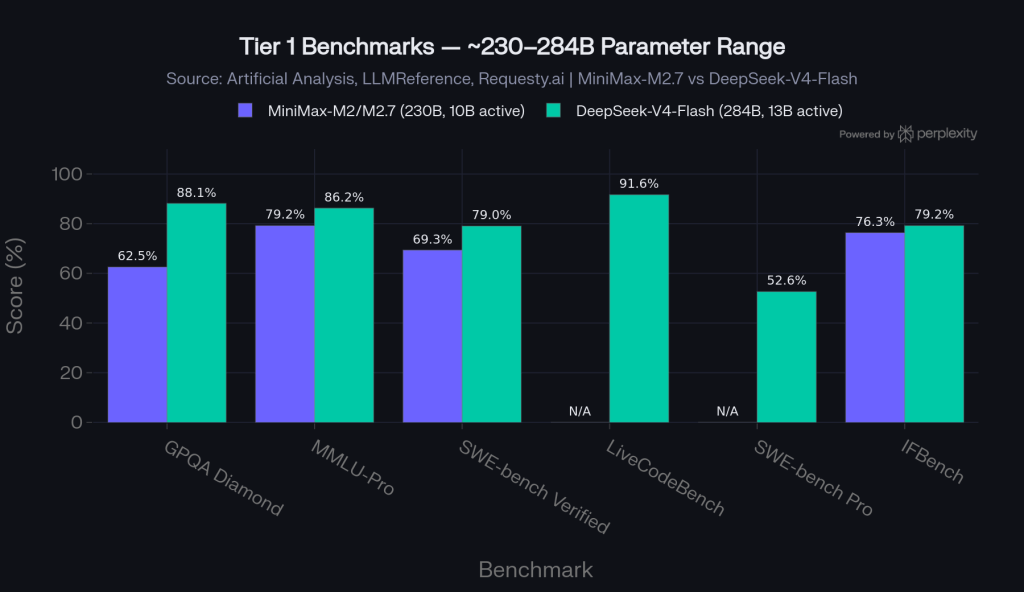
DeepSeek-V4-Flash leads on GPQA Diamond (88.1% vs 62.5%) and SWE-bench Verified (79.0% vs 69.3%), reflecting its stronger scientific reasoning and code resolution capabilities. MiniMax-M2/M2.7 compensates with better instruction-following (IFBench 76.3% vs 79.2% — within noise) and a strong MMLU-Pro score of 79.2%. For routine agentic tasks — classification, extraction, multi-turn conversations — the gap is small enough that pricing becomes the decisive factor.
Pricing efficiency
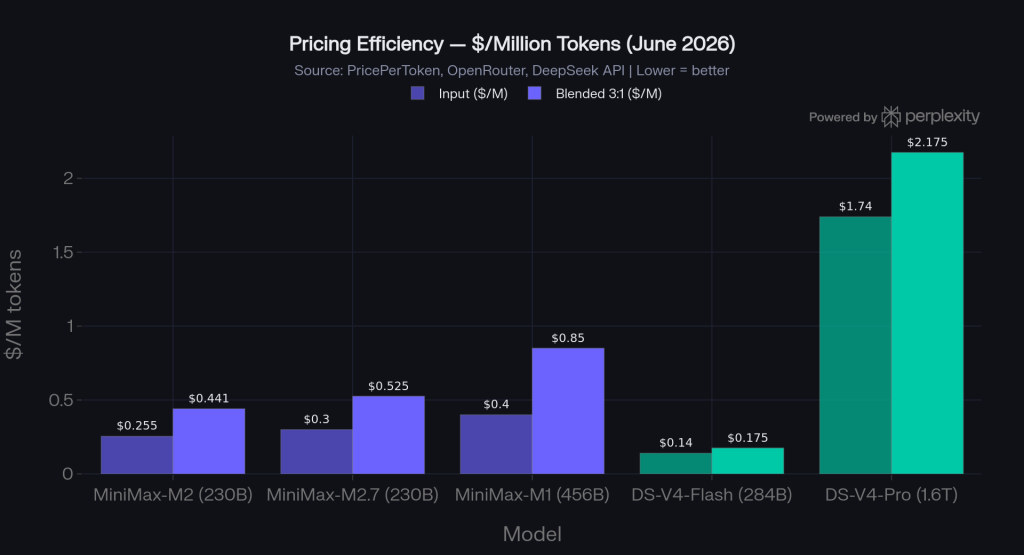
MiniMax-M2 costs $0.255/M input and $1.00/M output tokens. MiniMax-M2.7 is priced at $0.30/$1.20. DeepSeek-V4-Flash is the cheapest in this tier at $0.14/M input and $0.28/M output. If pure cost optimization is the goal, V4-Flash wins — it is roughly 45% cheaper than M2.7 per input token. If you need better instruction-following, streaming reliability, or a smaller self-hosting footprint for FP8 deployment, M2 remains competitive
Context window
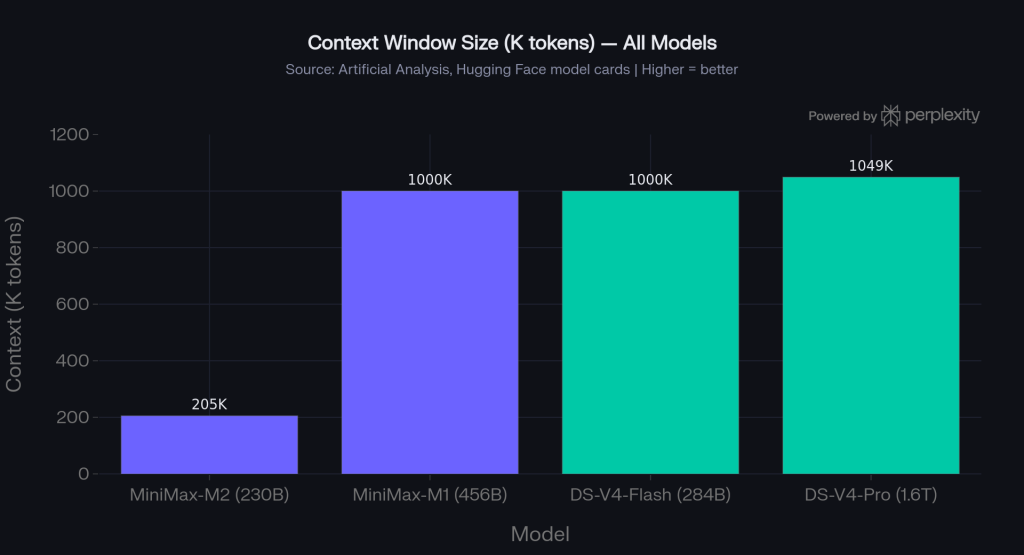
This is the starkest difference in Tier 1: DeepSeek-V4-Flash supports 1M tokens, while MiniMax-M2/M2.7 caps at 205K tokens. For most customer-facing and batch extraction workflows 205K is sufficient, but for full-codebase analysis, large PDF review, or long multi-agent memory chains, V4-Flash wins clearly.
Throughput and latency
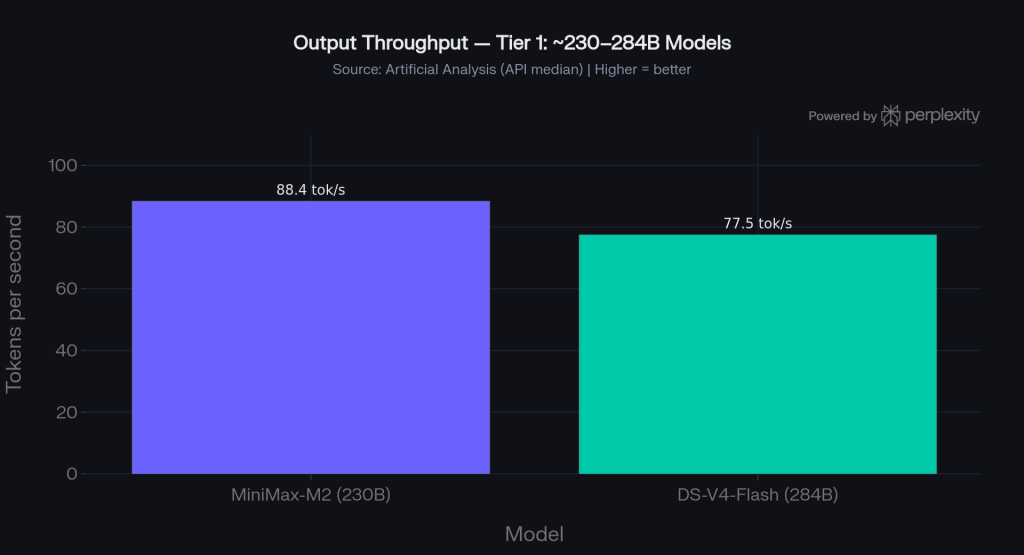
MiniMax-M2 generates 88.4 tokens/second; V4-Flash reaches 77.5 tokens/second. For streaming interfaces where generation speed matters, M2 has the edge. Time-to-first-token (TTFT including reasoning warm-up) is 1,339ms for M2 vs 765ms for V4-Flash — V4-Flash starts faster, M2 finishes faster. The right choice depends on whether your UX is latency-sensitive at the first token or at completion.
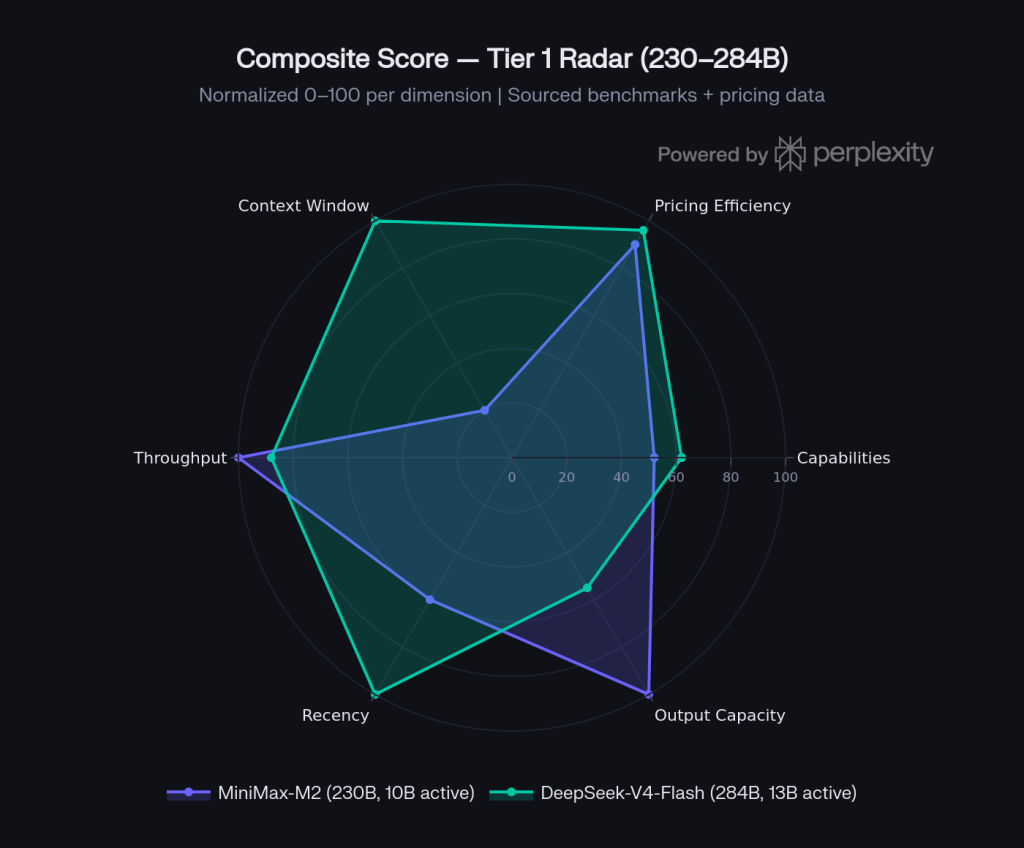
Tier 1 composite score
| Dimension | MiniMax-M2/M2.7 | DeepSeek-V4-Flash |
|---|---|---|
| Capabilities (normalized) | 52 / 100 | 62 / 100 |
| Pricing efficiency | 90 / 100 | 96 / 100 |
| Context window | 20 / 100 | 100 / 100 |
| Throughput | 100 / 100 | 88 / 100 |
| Recency | 60 / 100 | 100 / 100 |
| Output capacity | 100 / 100 | 55 / 100 |
Source: normalized from Artificial Analysis, PricePerToken, LLMReference
Verdict
DeepSeek-V4-Flash wins on context window, raw intelligence, and recency, MiniMax-M2.7 wins on throughput and output capacity. At this tier, V4-Flash is the stronger all-rounder for new architectures built in 2026.
Tier 2 — 456B vs frontier reasoning: MiniMax-M1 vs DeepSeek-V4-Pro
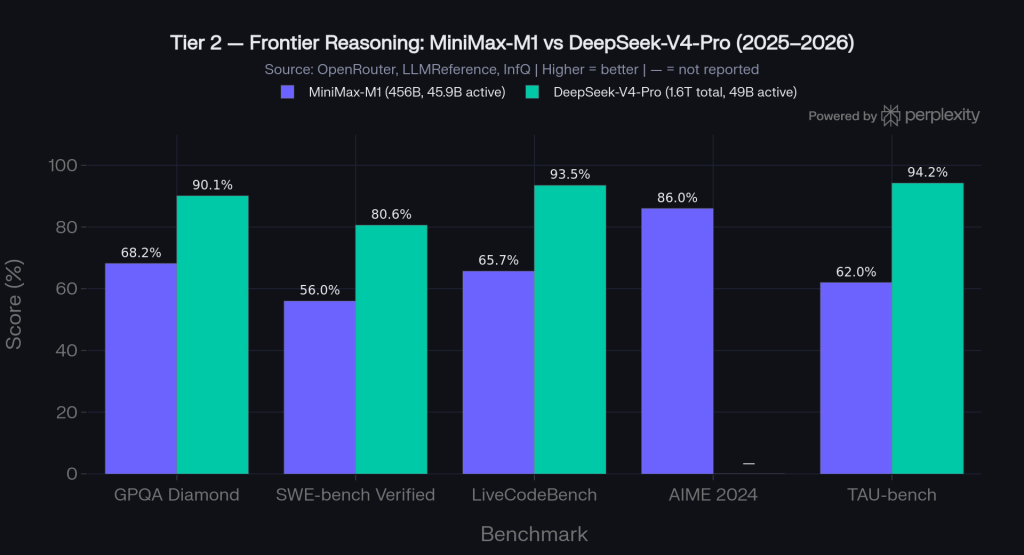
Benchmark comparison
DeepSeek-V4-Pro is ahead on every benchmark that requires frontier scientific reasoning and hard coding: GPQA Diamond 90.1% vs M1’s 68.2%, SWE-bench Verified 80.6% vs 56.0%, LiveCodeBench 93.5% vs 65.7%. MiniMax-M1 leads on AIME 2024 (86.0% vs not published for V4-Pro) and MATH-500 (97.2%), suggesting stronger mathematical problem-solving in competition-style tasks. For complex multi-step engineering agents and long-horizon tasks, V4-Pro is the better choice.
Pricing
| MiniMax-M1 | DeepSeek-V4-Pro | |
|---|---|---|
| Input ($/M) | $0.40 | $1.74 |
| Output ($/M) | $2.20 | $3.48 |
| Blended 3:1 | ~$0.85 | ~$2.17 |
MiniMax-M1 is approximately 2.5× cheaper per blended token than V4-Pro, with comparable active-parameter count (45.9B vs 49B). If your task needs strong reasoning but your budget is constrained, M1 is the most cost-efficient path in this tier.
Tier 2 composite score
| Dimension | MiniMax-M1 | DeepSeek-V4-Pro |
|---|---|---|
| Capabilities (normalized) | 66 / 100 | 100 / 100 |
| Pricing efficiency | 72 / 100 | 68 / 100 |
| Context window | 100 / 100 | 100 / 100 |
| Throughput | 55 / 100 | 40 / 100 |
| Recency | 40 / 100 | 100 / 100 |
| Output capacity | 80 / 100 | 100 / 100 |
Verdict
DeepSeek-V4-Pro dominates on raw intelligence, recency, and output capacity. MiniMax-M1 is the better choice when you need frontier-adjacent reasoning at lower cost with 1M context — particularly for long-context batch jobs that don’t require the top 5% of reasoning capability.
Operational use case matrix
| Use case | Tier 1 winner | Tier 2 winner | Notes |
|---|---|---|---|
| Coding & code review | DS-V4-Flash | DS-V4-Pro | Flash: SWE-bench 79.0%; Pro: 80.6%, LiveCodeBench 93.5% |
| Long document analysis | DS-V4-Flash | Both (1M ctx) | Flash and M1/Pro all support 1M tokens |
| Batch extraction / classification | MiniMax-M2 | MiniMax-M1 | Higher throughput, lower cost per token |
| Creative writing & chat | MiniMax-M2.7 | MiniMax-M1 | Better IFBench, higher throughput for streaming |
| Image / OCR | Neither | Neither | Both tiers are text-only in open-weights releases |
| Real-time latency | MiniMax-M2 | — | 88.4 tok/s vs 77.5 tok/s (V4-Flash) |
| Agentic multi-step reasoning | DS-V4-Flash | DS-V4-Pro | TAU-bench v2: Flash 95.0%; Pro 94.2% |
FAQ
MiniMax-M2 and MiniMax-M2.7 — what is the difference?
Same 230B/10B MoE architecture. M2.7 was trained with a self-improvement loop that improved SWE-Pro score to 56.2% and reached #1 on the Artificial Analysis Intelligence Index (50/100) in March 2026. Pricing: $0.30/$1.20 vs $0.255/$1.00 for M2.
Is DeepSeek-V4-Flash a real open-weights model or just an API product?
V4-Flash is fully open-weight under MIT license. Weights are on Hugging Face. Hardware requirement is ~158GB FP4+FP8 — self-hosting on 2× H200 is practical.
Can MiniMax-M1 handle 1M context reliably?
Yes. M1 was designed around 1M-token context from the start, and its lightning attention mechanism makes long-context inference efficient: at 100K generation tokens it uses 25% of the FLOPs of DeepSeek-R1. Practical VRAM limits still apply when self-hosting.
For a GDPR-compliant RAG pipeline, which model should I use?
V4-Flash at Tier 1 is the strongest option: 1M context, strong retrieval reasoning, lowest cost in its parameter class. Self-host on European infrastructure (vLLM, 2× H200) and data never leaves your perimeter.
Which model is better for Italian or multilingual tasks?
MiniMax-M2.7 has documented multilingual and instruction-following strengths (IFBench top scores among open-source). Neither publishes explicit Italian benchmarks — test on your own data before committing to a production architecture.
Start your free 30-day trial at regolo.ai and deploy LLMs with complete privacy by design.
👉 Talk with our Engineers or Start your 30 days free →
- Discord – Share your thoughts
- GitHub Repo – Code of blog articles ready to start
- Follow Us on X @regolo_ai
- Open discussion on our Subreddit Community
Built with ❤️ by the Regolo team. Questions? regolo.ai/contact or chat with us on Discord