Both MiniMax M2.7 and Kimi K2.5 are open-weight Mixture-of-Experts models released in early 2026 that punch well above their cost class. They are not interchangeable, though: Kimi K2.5 dominates on math, science reasoning, and visual/document intelligence, while MiniMax M2.7 wins on end-to-end software engineering delivery, office-productivity agentic tasks, and raw price-per-token efficiency. The right choice depends almost entirely on what your production workload actually needs.
What these two models actually are
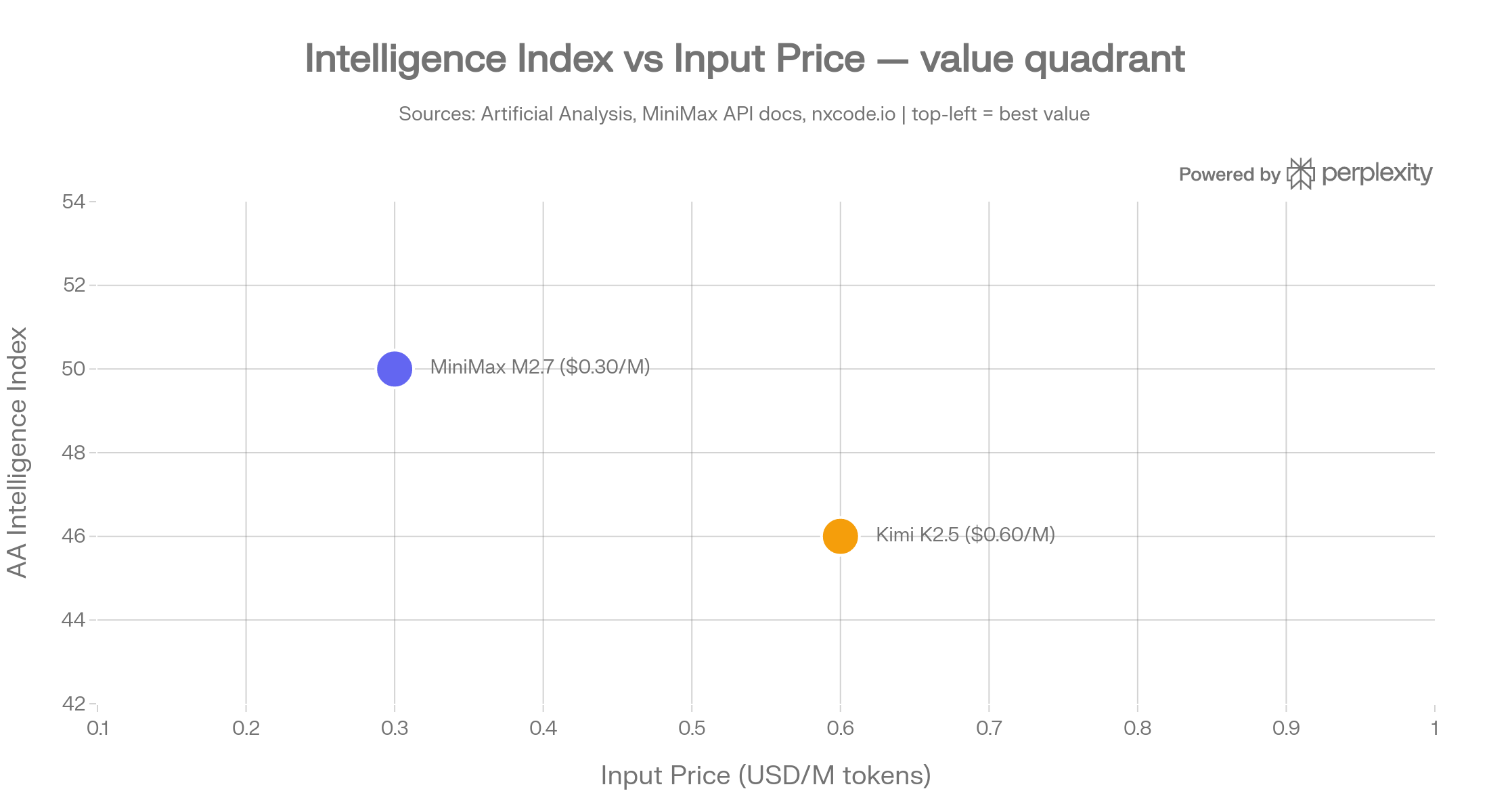
MiniMax M2.7 is the March 2026 flagship from Shanghai-based MiniMax. It uses a sparse MoE architecture with 230 billion total parameters but only 10 billion active per inference step. That design choice — small active footprint, large capacity — is why the model runs at roughly 45 tokens per second while costing just $0.30 per million input tokens on the standard tier and $0.60/M on the high-speed tier. The 205K-token context window is large, but it is not the widest in its class. A non-commercial research license limits how teams can deploy the weights; commercial use requires a separate agreement.
The benchmark picture
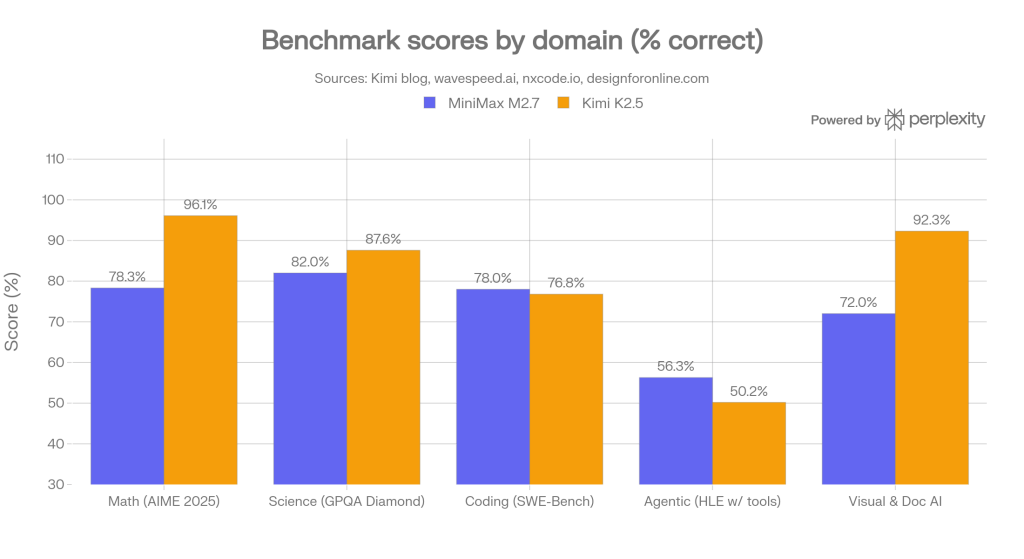
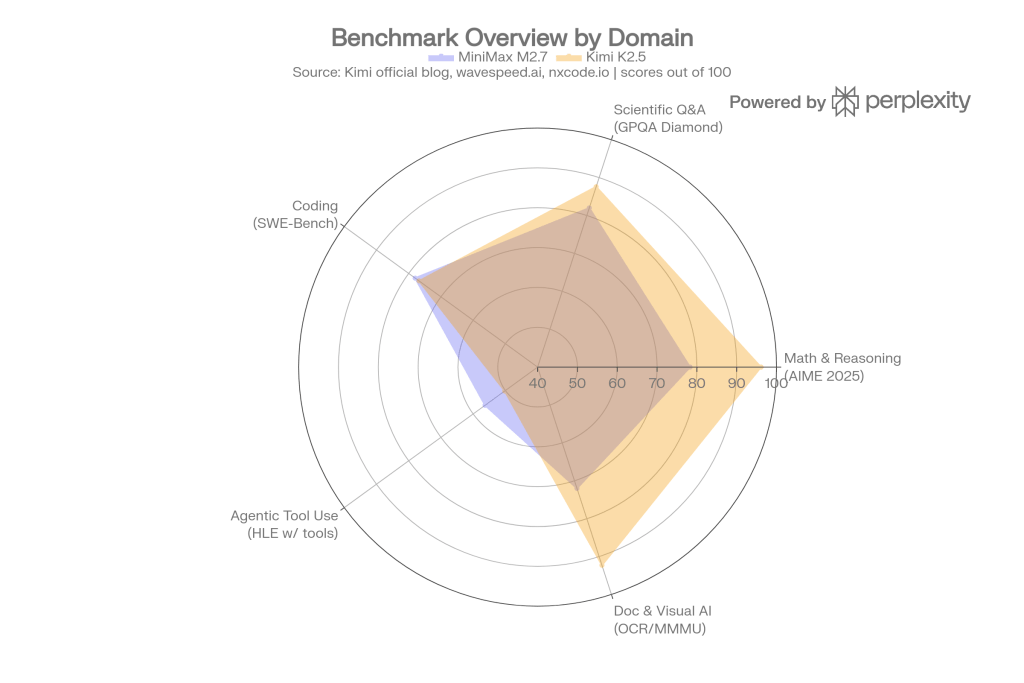
The pattern across domains is consistent: Kimi K2.5 leads strongly on math and science reasoning and on visual/document AI, while MiniMax M2.7 holds competitive or superior ground on end-to-end software engineering tasks, especially full-project delivery.
Math and scientific reasoning
Kimi K2.5 scores 96.1% on AIME 2025 and 87.6% on GPQA Diamond, the graduate-level science benchmark. MiniMax M2.7 scores approximately 78.3% on AIME and 82% on GPQA Diamond — solid scores, but a 10–18 point gap that matters for any workload requiring rigorous multi-step derivation or expert-level scientific judgment.
Software engineering
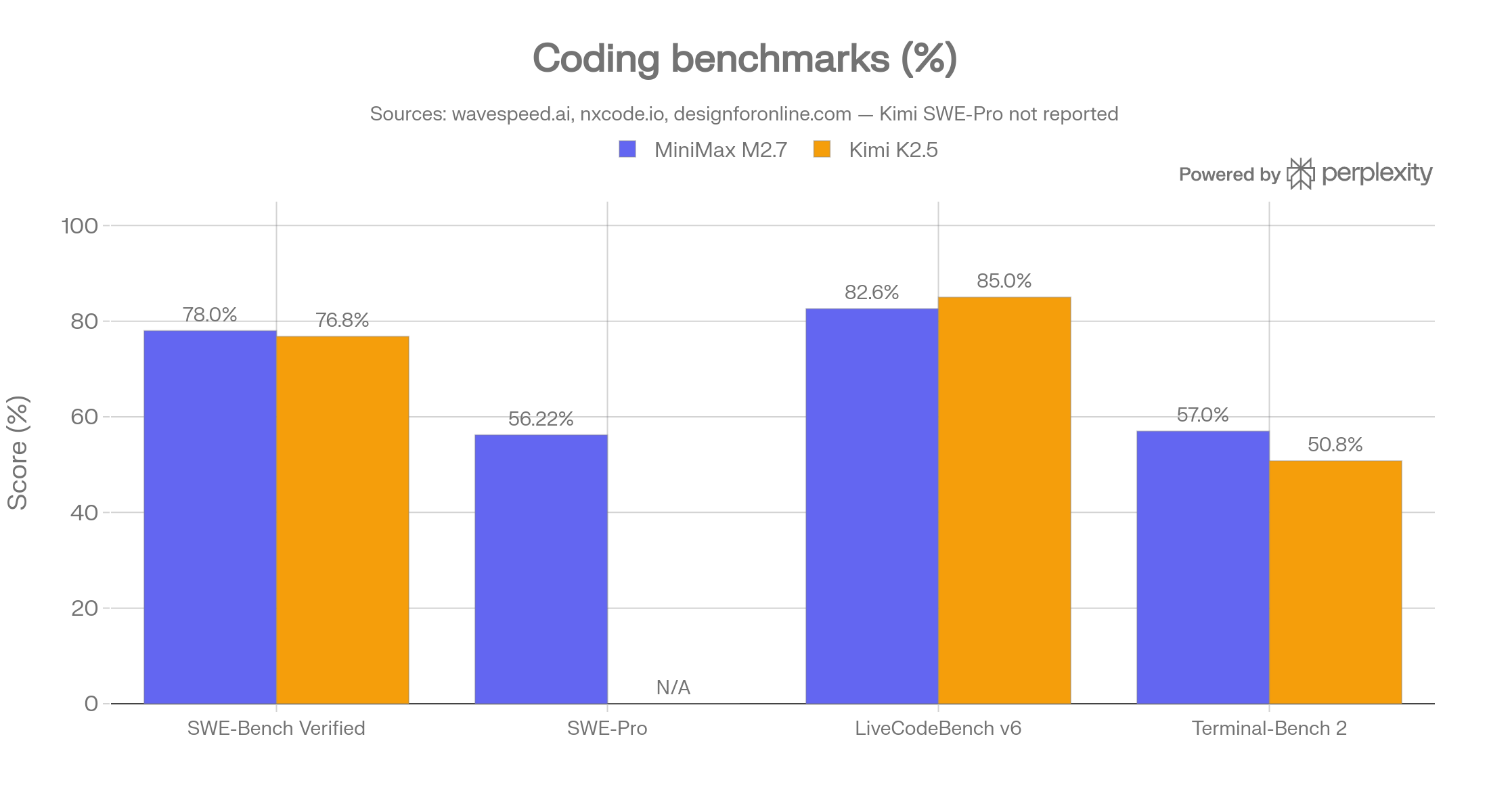
Here the picture inverts. MiniMax M2.7 scores 78% on SWE-Bench Verified, 56.22% on SWE-Pro, and 55.6% on VIBE-Pro (end-to-end project delivery), placing it near or above Claude Opus 4.6 on those benchmarks. Kimi K2.5 scores 76.8% on SWE-Bench Verified and 85.0% on LiveCodeBench v6 (competitive programming), so it is stronger on pure algorithmic problem-solving, but weaker on the messier, real-world multi-file delivery scenarios that VIBE-Pro measures.
Real-world agentic coding tests on Next.js/Convex codebases confirm this: MiniMax M2.7 produced roughly 5 review fixes per session while Kimi K2.5 produced approximately 50 — Kimi ships features faster but leaves more integration debt, while MiniMax behaves as a more conservative, lower-error coder.
Visual and document intelligence
Kimi K2.5 scores 92.3% on OCRBench and 88.8% on OmniDocBench 1.5, making it the best open-source model for workflows that process scanned documents, UI screenshots, or PDF tables. MiniMax M2.7 does not support image input, which is a hard constraint for any multimodal pipeline.
Agentic tool use
Kimi K2.5 scores 50.2% on HLE-Full with tools (vs 45.5% for GPT-5.2 and 43.2% for Claude Opus 4.5), demonstrating strong performance when the model needs to orchestrate web browsing, code execution, and information synthesis in a single session. MiniMax M2.7’s agentic strength lies in office-productivity pipelines: it holds the highest ELO score (1,495) among open-source models on GDPval-AA, which evaluates real-world work tasks across Excel, Word, and complex document editing, with 97% skill adherence across 40+ simultaneous tasks each exceeding 2,000 tokens.
Price, speed, and context
MiniMax M2.7 at $0.30/M input tokens is approximately 2× cheaper than Kimi K2.5 at $0.60/M.
At one million tokens per day, that translates to roughly a $13/month cost difference — meaningful when running high-throughput pipelines.
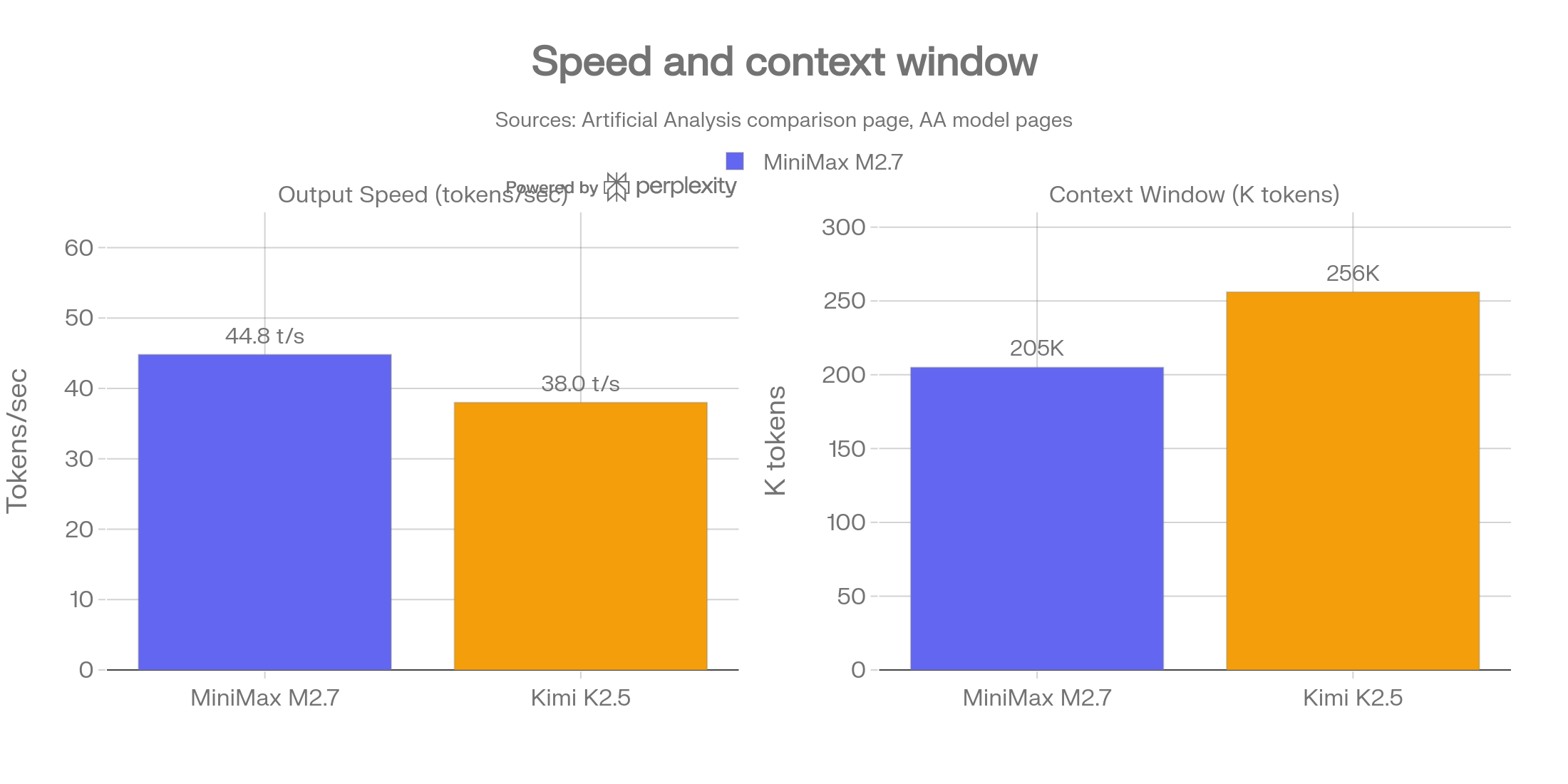
MiniMax M2.7 runs at ~45 tokens per second on the standard tier (the high-speed tier reaches ~100 t/s), while Kimi K2.5 runs at approximately 38 tokens per second in typical API conditions. Kimi K2.5 offers a wider 256K-token context window vs MiniMax M2.7’s 205K, relevant when ingesting very long documents in a single pass.
AI code assistants and autonomous coding agents
Use MiniMax M2.7 when code quality and low review overhead matter. Its 78% SWE-Bench Verified and 56.22% SWE-Pro scores sit at or above Opus 4.6 levels, and the real-world test across 48h of Next.js/Convex work showed ~5 review fixes vs ~50 for Kimi. For teams shipping production code where a human reviews every PR, lower error rate is worth more than raw speed-of-feature-shipping.
Use Kimi K2.5 when the agent needs to research and reason deeply before writing code. Its superior HLE-with-tools score (50.2%) and web browsing capability (60.2 on Seal-0 vs GPT-5’s 54.9) make it the better choice for research-driven engineering tasks: gathering API documentation, cross-referencing issue trackers, synthesising context from multiple repos before writing. Its 85% LiveCodeBench v6 score also makes it stronger for competitive or algorithmically dense problems.
Document processing and RAG pipelines
Use Kimi K2.5. The 92.3% OCRBench and 88.8% OmniDocBench scores mean it will handle scanned PDFs, mixed-language invoices, tables, and UI screenshots with far fewer errors than any model that ignores visual input.
Office productivity automation and enterprise workflows
Use MiniMax M2.7. The GDPval-AA ELO of 1,495 (highest among open-source models) and 97% skill adherence across complex multi-step tasks were measured specifically on Excel, PowerPoint, Word, and long-form document editing workflows.
For a CTO building an internal assistant that generates financial models, drafts presentations, cross-references reports, or processes high volumes of mixed-format business documents — and needs to do it cheaply at scale — MiniMax M2.7 at $0.30/M is the defensible choice.
Running both models on Regolo
We run open models on GPU infrastructure based entirely in europe — no transatlantic data flows, no data retention at inference time, and full alignment with GDPR and the direction of the EU AI Act. Both MiniMax M2.7 and Kimi K2.5 are available through our OpenAI-compatible API, which means switching between them is a one-line change.
You can deploy using our custom models, following the guided wizard into your dashboard and use the deployed model with OpenAI-Compatible API,
from openai import OpenAI
# Switch models by changing MODEL_ID_PLACEHOLDER only
# No other code changes required — same API, same endpoint
client = OpenAI(
api_key="REGOLO_API_KEY",
base_url="https://api.regolo.ai/v1"
)
def run(model_id: str, user_message: str) -> str:
r = client.chat.completions.create(
model=model_id,
messages=[{"role": "user", "content": user_message}]
)
return r.choices.message.content
# Use MiniMax M2.7 for cost-sensitive extraction
extraction_result = run("MODEL_ID_PLACEHOLDER_MINIMAX", "Extract the key clauses from this contract: ...")
# Use Kimi K2.5 for reasoning-heavy analysis
analysis_result = run("MODEL_ID_PLACEHOLDER_KIMI", "Analyse the scientific validity of this study methodology: ...")Code language: PHP (php)Quick decision table
| Workload | Recommended model | Deciding factor |
|---|---|---|
| Backend API / data extraction | MiniMax M2.7 | Lower cost, high throughput |
| End-to-end coding agent (low error rate) | MiniMax M2.7 | 78% SWE-Bench, ~5 review fixes |
| Research-driven coding (deep reasoning) | Kimi K2.5 | HLE w/ tools 50.2%, web browsing[ |
| Document & OCR pipelines | Kimi K2.5 | Image input, 92.3% OCRBench |
| Scientific / medical reasoning tools | Kimi K2.5 | GPQA 87.6%, AIME 96.1% |
| Office productivity automation | MiniMax M2.7 | GDPval-AA ELO 1,495[ |
| User-facing chat / interactive apps | MiniMax M2.7 | ~45–100 t/s, $0.30/M |
| Long-document RAG (very long docs) | Kimi K2.5 | 256K context, image support |
| Cost-sensitive high-volume production | MiniMax M2.7 | 2× cheaper input |
FAQ
Q: Can I use MiniMax M2.7 commercially?
Not without a separate license agreement. The default weights are released under a non-commercial license. Kimi K2.5 ships under a Modified MIT License that supports commercial use without restrictions. If you need production deployment without licensing overhead, Kimi K2.5 is the cleaner path — or use either model through an inference provider like Regolo.ai, which handles licensing at the API layer.[^1]
Q: MiniMax M2.7 has only 10B active parameters. Does that mean it is weaker?
No — it means it is faster and cheaper at inference time. The MoE architecture routes each token through 10B of the 230B total capacity, selecting the most relevant experts per token. The full 230B parameters are trained and available; the routing just activates a subset per forward pass. On benchmarks like SWE-Bench Verified (78%), the model performs at Opus 4.6 levels despite the smaller active footprint.[^2]
Q: Kimi K2.5 is described as a “reasoning model” — does that mean it is slow?
It can be, for reasoning-intensive prompts. Kimi K2.5 Thinking uses extended chain-of-thought before answering, which increases latency for complex questions. For simpler tasks you can reduce the reasoning budget or use a non-thinking mode if available. If latency is the primary constraint, MiniMax M2.7 is the safer default.[^1]
Q: Can I run both models through Regolo.ai’s API?
Yes. Both are available through the Regolo.ai inference API with zero data retention at the provider level. Because we operate entirely within Italian data centres, your inference traffic stays within EU jurisdiction. Check the latest model catalogue at regolo.ai for current availability and model IDs.
Q: Which model is easier to fine-tune?
Both weights are open, but fine-tuning a 1T parameter MoE (Kimi K2.5) is substantially more hardware-intensive than fine-tuning a 230B MoE (MiniMax M2.7). For teams with 1–2 H100s, MiniMax M2.7 is the more tractable fine-tuning target. That said, for most teams, prompt engineering and RAG on top of either model through the Regolo.ai API will be faster to production than a fine-tuning project.
Q: What if I need both capabilities — coding AND visual document processing?
A practical pattern is to route tasks at the application layer: send code generation and extraction tasks to MiniMax M2.7, and send document parsing or vision-heavy tasks to Kimi K2.5. Because both models expose an OpenAI-compatible API, the routing logic is a simple model-ID selector. This gives you the cost efficiency of MiniMax M2.7 for the high-volume paths while reserving Kimi K2.5 for the tasks where its visual and reasoning advantages actually matter.
rt your free 30-day trial at regolo.ai and deploy LLMs with complete privacy by design.
👉 Talk with our Engineers or Start your 30 days free →
- Discord – Share your thoughts
- GitHub Repo – Code of blog articles ready to start
- Follow Us on X @regolo_ai
- Open discussion on our Subreddit Community
Built with ❤️ by the Regolo team. Questions? regolo.ai/contact or chat with us on Discord
When deploying these models in production, choosing an EU-based inference provider ensures your prompts aren’t used for future training.