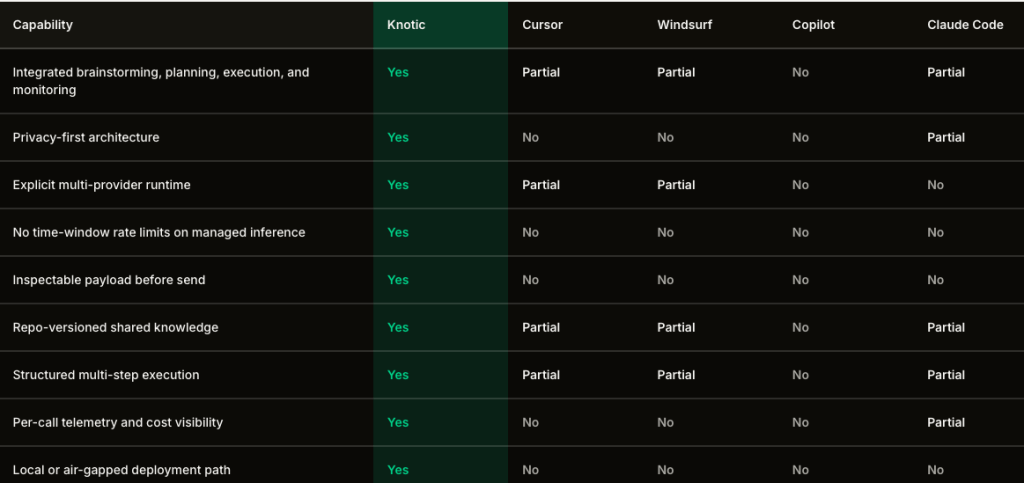
Traditional AI IDEs fail because they mix persistent codebase rules with transient session transcripts, leading to hallucinations and skyrocketing API costs. Knotic solves this context drift by splitting memory into three layers: long-term project knowledge, live session state, and a source-oriented documentary wiki. When combined with Regolo Brick’s spatial capability routing, simple memory tasks like session compression are handled by fast, low-cost models, reserving expensive frontier engines only for hard logical reasoning.
This architectural union slashes operational costs by up to 22x while maintaining high-fidelity code generation and complete compliance with European data privacy laws.
Table of Contents
- European data sovereignty for private intellectual property
- The context drift crisis in AI coding tools
- The architecture of layered memory: project, session, and wiki
- Enter Brick: mapping memory tasks to spatial capabilities
- Cost and latency optimization in autonomous engineering loops
- How to implement Brick with a tiered memory system
The problem with vibe coding
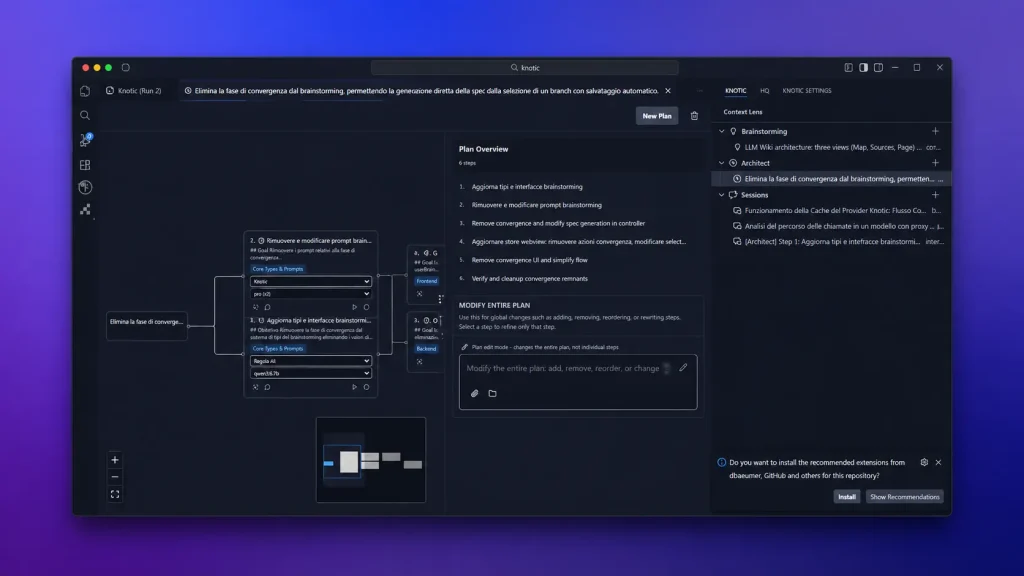
Right now, a lot of developers are stuck in a loop of generating code, pasting it, and watching it fail, and wastes time. Artiforge forked Visual Studio Code to build Knotic, an environment that tries to understand the actual codebase context.
You can run models locally or connect to your OpenAI Compatible provider in the settings.
Managing tokens and real money
Knotic addresses context drift by separating memory into three distinct, specialized layers, each serving a specific operational role. This structured approach prevents the system from becoming overloaded with redundant information.
┌────────────────────────────────────────────────────────┐
│ INCOMING USER PROMPT │
└───────────────────────────┬────────────────────────────┘
▼
┌────────────────────────────────────────────────────┐
│ KNOTIC THREE-LAYER MEMORY │
├────────────────────────────────────────────────────┤
│ 1. Long-Term Project Memory │
│ - Persistent rules, conventions, landmarks │
├────────────────────────────────────────────────────┤
│ 2. Live Session Memory │
│ - Active task progress, decisions, tool outputs │
├────────────────────────────────────────────────────┤
│ 3. Documentary LLM Wiki │
│ - Raw source documents, sitemaps, guide files │
└─────────────────────────┬──────────────────────────┘
▼
┌────────────────────────────────────────────────────┐
│ REGOLO BRICK ROUTER ENGINE │
├────────────────────────────────────────────────────┤
│ - Analyzes prompt across 6 spatial dimensions │
│ - Cost-penalized geometric dispatch in < 50ms │
└─────────────────────────┬──────────────────────────┘
├──────────────────────────┐
▼ ▼
[ FRONTIER MODEL ] [ ECO MODEL ]
e.g., Brick, Opus, Fable e.g., Llama-3-8B
Complex Reasoning, Compression,
Code Refactoring Keyword ExtractionCode language: CSS (css)1. Long-term Project Memory
This layer stores the core knowledge that an AI assistant needs to understand about a repository before it even opens a file including:
- Stable architectural conventions and design patterns.
- Key subsystem relationships and file-system landmarks.
- Library dependency boundaries.
- Recurrent flow logic and specific coding guidelines.
Instead of forcing developers to write the same explanations in every prompt, Knotic promotes verified, durable facts from individual sessions into this stable project backbone.
2. Live session memory
This layer tracks the active state of the current work item. It records:
- The immediate user requests and assistant replies.
- Concrete outcomes from running terminal tools or unit tests.
- Intermediate decisions taken during the session (such as selecting one library over another).
- Pointers to files that have been read or modified.
This short-term working memory is crucial for task continuity. It keeps the assistant oriented during a multi-step debugging or implementation flow. However, because long sessions quickly become bloated, this layer is compressed periodically. Older transcripts are summarized into compact checkpoints to preserve the context signal without dragging the entire history forward.
3. Documentary memory through the LLM Wiki
The third layer serves as a curated library of reference materials. It houses:
- Developer guidelines and onboarding documentations.
- Specific system architectures and internal API guides.
- External API specifications or compliance requirements.
There is a subtle but essential difference between project memory and this wiki layer: Project memory stores highly condensed, abstract understandings of the codebase. The LLM Wiki keeps raw, source-oriented materials intact and Knotic uses policies to decide when to inject the full text of a wiki document or when to only expose its index, ensuring the assistant reads the exact source when necessary.
Breaking down complex tasks
Instead of relying on one massive prompt to build a feature, Knotic breaks tasks down using specialized agents.
The Brainstorming agent handles initial ideas, and the Architect maps out the steps, because they divide the work into smaller chunks, you don’t always need a massive, expensive model. Smaller, cheaper models handle these tightly scoped tasks perfectly well.
Regolo and Brick: mapping memory tasks to spatial capabilities, up to 80% costs
Knotic uses an OpenAI-compatible API, meaning you can plug Regolo straight in – this routes your inference through European infrastructure with a strict zero data retention policy. They also runs on a credit-based model rather than unlimited subscriptions, you pay for what you use, and you are never locked into a single provider. The free version covers basic chat, while the paid tier unlocks the agents.
You can setup one model (Brick) as gateway for all available Core Models relying its Spatial Capability Routing (detailed in the peer-reviewed paper Brick: Spatial Capability Routing for the Mixture-of-Models Paradigm, arXiv:2606.13241).
How does it works? When a request comes in, Brick projects the prompt into a geometric vector space across six distinct capability dimensions:
- Logical Reasoning & Math
- Coding & Syntax Proficiency
- Structured Language Modeling (JSON/YAML formatting)
- Multilingual Depth
- Creative & Open-Ended Synthesis
- Retrieval & Context-Length Management
Memory task routing framework
Here is how Knotic’s layered memory operations are automatically routed when integrated with Brick:
| Memory Operation | Key Cognitive Dimensions Required | Recommended Model Tier | Cost Optimization Factor |
|---|---|---|---|
| Session Compression & Checkpointing | Structured Language Modeling, Basic Logic | Eco Tier (e.g., Llama-3-8B) | 22.15x savings |
| Landmark Extraction (Project Memory) | Retrieval & Context, JSON Output | Balanced Tier (e.g., Qwen3.5-32B) | 4.71x savings |
| LLM Wiki Query & Classification | Semantic Density, Retrieval | Balanced Tier (e.g., Qwen3.5-32B) | 4.71x savings |
| Complex Code Generation & Refactoring | High Logical Reasoning, Advanced Coding | Frontier Tier (e.g., Claude 3.5 Sonnet) | Baseline |
Cost and latency optimization in autonomous engineering loops
In a Loop Engineering paradigm, developers build autonomous, multi-agent pipelines that execute a continuous cycle: Discover → Plan → Execute → Verify → Iterate.
During this autonomous cycle, the agent makes dozens of background calls to read files, run tests, and check syntaxes.
- If the agent calls a frontier model for every single step, the cost of completing a simple 50-line refactoring task can quickly become unsustainable.
- With Brick, the autonomous loop remains highly cost-effective because the agent uses the expensive frontier brain to Plan the overall architectural changes, uses a lightweight model to Execute the direct edits, and calls a medium model to Verify the terminal outputs against unit tests.
The numbers from Brick’s empirical benchmarks (tested across 5,504 multi-turn enterprise queries) demonstrate the strength of this design:
- Max-Quality Profile: actually outperfomed single-frontier deployments by nearly two percentage points (76.98% vs 75.02%) because smaller, focused models avoid overthinking simple prompts.
- Balanced Profile: reduced API costs by 4.71x while maintaining identical performance to pure frontier models.
- Min-Cost Profile: slashed costs by an incredible 22.15x, making high-frequency agent loops economically viable for small and large teams alike.
What is coming next
By the end of the year, Knotic plan to ship enterprise features like SSO and custom security policies, they are also building a Pull Request Review tool to bring the Git workflow directly into the editor.
It’ i’s an ambitious roadmap, but the focus on privacy and structure feels like the right direction.
FAQ
What is Knotic?
It is an IDE built on a VS Code fork that focuses on context management and token optimization for AI-assisted coding.
How does it reduce API costs?
It caches system prompts for up to 20 minutes to cut down on redundant token usage and provides dashboards to track spending.
Does it force you to use a specific AI model?
No. You can run open-source models locally or connect to any provider with an OpenAI-compatible API, including Regolo.
How does Knotic prevent its session memory from becoming too large?
Knotic uses an automated checkpointing process. When the session transcript grows too large, the system uses a low-cost model routed by Brick to compress the historical details into a structured JSON summary, preserving key decisions and file paths while discarding redundant tool logs.