
Artificial intelligence is simultaneously our most promising tool for fighting climate change and one of its fastest-growing contributors. As AI adoption accelerates globally, the infrastructure powering it — data centers, GPUs, cooling systems — is consuming energy, water, and rare minerals at a pace that risks undermining the very sustainability goals AI is meant to help us achieve. The path forward is not to slow down AI, but to build it differently: with ethical choices around model efficiency, infrastructure, and provider accountability at every layer of the stack.
What the paradox actually means
The term “Green AI Paradox” describes a fundamental tension: AI can reduce industrial energy consumption by 30–50% through optimization and smart grid management, yet the electricity consumed by global data centers is projected to exceed 1,000 TWh by 2030 — roughly equivalent to the entire annual electricity consumption of Germany. That growth is not incidental. It follows directly from the explosive adoption of large language models, image generators, and AI-driven services that now handle billions of requests per day.
This dynamic is sometimes called a “rebound effect” or Jevons’ Paradox: efficiency gains at the model level stimulate greater adoption, longer prompts, more complex tasks, and larger infrastructure buildouts, ultimately increasing total energy demand even as each individual inference becomes cheaper. No empirical study has yet fully quantified these higher-order societal effects, but the direction of the trend is clear.
A useful way to frame the paradox is as three simultaneous pressures: the operational energy cost of running models at scale, the embodied carbon of building the hardware to run them, and the rebound dynamics that make pure efficiency arguments insufficient on their own.
The real weight of inference
Credits to Stanford
Most public discussion about AI’s environmental footprint has historically focused on training — the massive, one-time GPU runs that produce a model like GPT or Llama. But that framing is increasingly outdated. A rigorous 2025 scoping review from UNIST found that inference — the everyday use of a deployed model — may account for more than 65–90% of the total carbon footprint across a model’s operational life, dwarfing training in cumulative terms. For a large language model processing billions of queries over its commercial lifetime, training is a small upfront cost; inference is the long tail that dominates.
The WEF confirms this split in its 2025 energy paradox report: across the AI lifecycle, model deployment accounts for approximately 60–70% of combined electricity consumption, with training contributing 20–40% and model development up to 10%. And crucially, the inference share will keep growing as adoption scales.
Put in human terms: a single LLM query consumes approximately 2.9 watt-hours of electricity, compared to just 0.3 watt-hours for a standard web search — nearly ten times more. Training a single large language model emits roughly 300,000 kg of CO₂, equivalent to around 125 round-trip flights between Beijing and New York. These are not abstract statistics. They represent real infrastructure decisions made every day, and they accumulate.
Data center electricity consumption in the US rose from 1.9% of total national usage in 2018 to 4.4% in 2023, and is expected to reach between 6.7% and 12.7% by 2028, with more than half of that increase attributable to AI alone.
Globally, annual electricity demand growth is now forecast to reach nearly 3.5% in the coming years, a figure that reflects not just AI but the broader electrification of transport, buildings, and industrial systems — all pressured simultaneously.
Three dimensions of environmental cost
The environmental cost of AI is not limited to carbon, a complete picture requires looking at energy, water, and materials together.
Energy and carbon
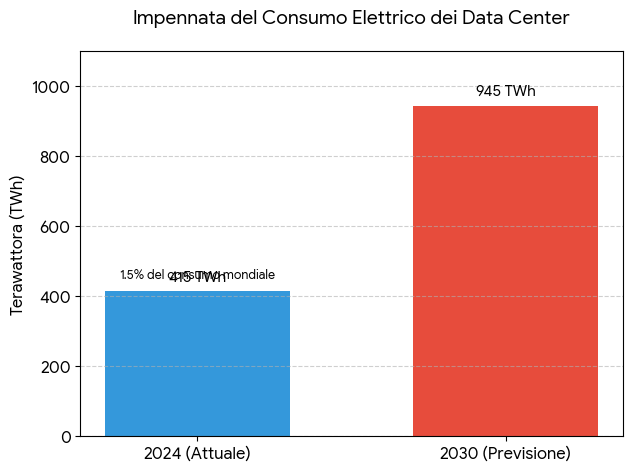
Global data centers consumed approximately 415 TWh of electricity in 2024, accounting for around 1.5% of the world’s total electricity consumption.
That figure is set to more than double by 2030, reaching around 945 TWh; the carbon intensity of this consumption depends heavily on where the data center sits and what energy mix powers it.
A model inference running on coal-fired grid power in one region can generate orders of magnitude more CO₂ than the same operation running on renewables elsewhere — even with identical hardware and identical code.
This is why the geographic location of a provider’s data center is not a logistical detail. It is an ethical decision.
Water stress
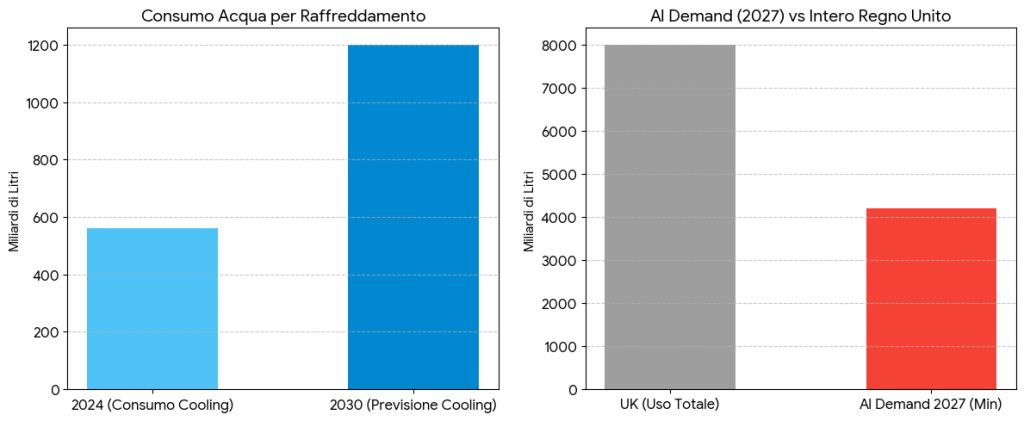
Data centers consumed approximately 560 billion liters of water annually as of 2024 for cooling purposes, a figure set to reach around 1,200 billion liters by 2030. Global AI-related water demand is projected to hit 4.2–6.6 billion cubic meters by 2027 — exceeding 50% of the UK’s entire annual water use. In regions already facing drought or water scarcity, co-locating a large data center with those communities creates direct competition for a finite resource.
Notably, not all data center cooling relies on water. Certain European operators use dry or air-based cooling systems that eliminate this footprint entirely — a design choice that matters but rarely makes headlines.
E-waste and rare materials
The rapid upgrade cycles of AI hardware — from one GPU generation to the next — generate growing volumes of electronic waste. Currently, only about 22% of global e-waste is disposed of in an environmentally sound way, the minerals and rare earth elements required to manufacture GPUs and AI accelerators overlap significantly with those needed for the low-carbon energy transition: lithium, cobalt, nickel, rare earths.
This means AI’s hardware demand creates direct competition with the renewable energy buildout it is simultaneously being asked to support
How efficiency techniques change the equation
There is genuine technical progress being made on the efficiency side. Two of the most practical levers are model quantization and optimized workload placement.
Quantization: doing more with less
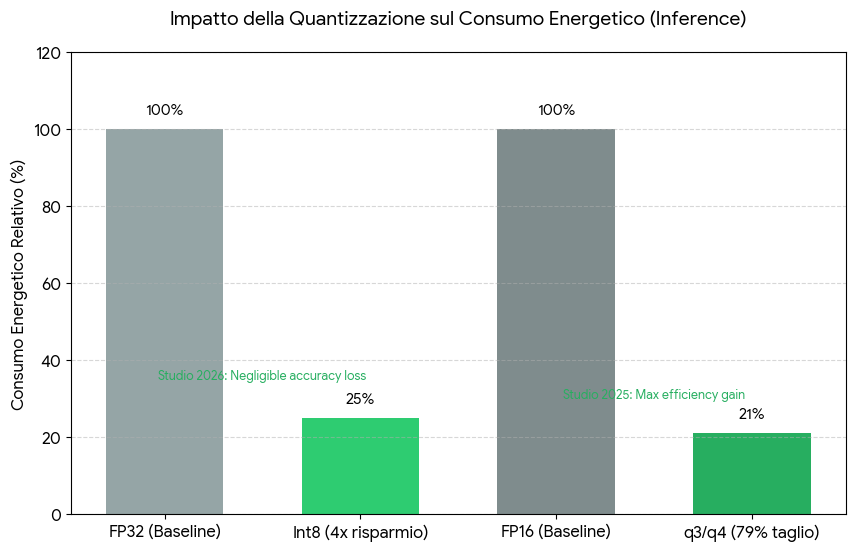
Model quantization — reducing the numerical precision of model weights from 32-bit or 16-bit floating point down to 8-bit or 4-bit integers — is one of the most effective tools available for reducing the energy cost of inference.
A 2026 study evaluating weight-only quantization strategies for LLM inference found that fused-kernel implementations such as EETQ int8 and Bitsandbytes int8 can offer energy savings of up to 4× compared to FP32 on short text generation tasks, with negligible accuracy loss.
A parallel study from April 2025 found that q3 and q4 quantization variants can cut energy use by up to 79% compared to FP16, though extreme quantization can introduce inefficiencies depending on task type.
The tradeoffs are real and must be managed carefully: some quantization levels degrade performance on mathematical reasoning or complex multi-step tasks more than on simpler queries. But for the vast majority of production inference use cases — summarization, classification, code completion, conversational assistants — well-chosen quantization delivers substantial efficiency gains with acceptable quality.
The practical implication is that choosing a quantized model variant is not just a performance decision. It is an environmental one.
Workload placement and green scheduling
Beyond individual model choices, how and where inference workloads are dispatched matters enormously.
Carbon-aware scheduling — routing compute jobs to grid periods or geographic locations with higher renewable penetration — can significantly reduce carbon intensity without changing the model or the hardware.
Microsoft Research has explored colocating AI inference clusters directly at wind farm sites, bypassing overburdened grids and running on abundant, underutilized green energy. Kubernetes autoscaling and spot instances can reduce overprovisioning by 30–50%, directly cutting wasted energy.
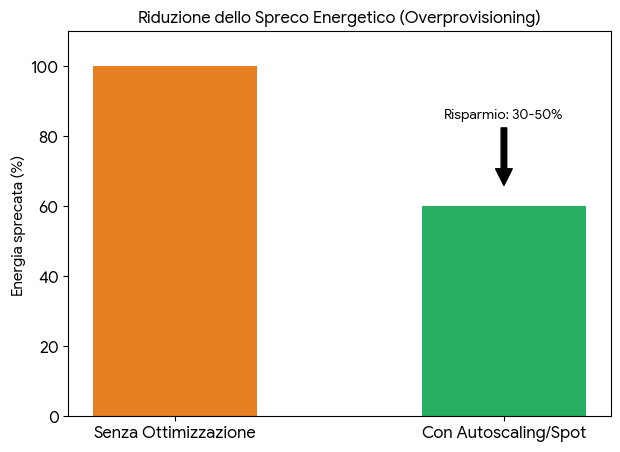
These are not futuristic ideas, they are architectural decisions that responsible inference providers can, and should, implement today.
What the research frameworks say we need
Several analytical frameworks have emerged to systematize the measurement and governance of AI’s environmental impact.
The Sustainable AI Impact Assessment Framework (SAIAF), cited across multiple recent studies, proposes evaluating AI systems across three dimensions: environmental (carbon footprint and lifecycle emissions), social (ethical considerations and labor implications), and economic (long-term efficiency rather than short-term output). The intent is to make sustainability a design constraint on AI systems, not an afterthought.
The Global AI Environmental Index, proposed at the AI Impact Summit 2026, aims to standardize cross-provider evaluation of water use, carbon intensity, and e-waste generation. The underlying problem it addresses is real: as a 2025 scoping review noted, current AI carbon accounting practices are fragmented, methodologically inconsistent, and suffer from technology-specific biases and insufficient end-to-end system perspectives. Without standardized measurement, there is no credible accountability.
The Planetary Health Alliance’s ProSocial AI framework goes further, framing AI governance as a tool for actively mitigating environmental decline rather than merely reporting on it. This requires integrating domain expertise, human-centered design, and contextual governance — because AI systems that optimize for narrow metrics without capturing the full complexity of environmental and social systems can cause harm even while appearing efficient.
At the regulatory level, the EU AI Act (Chapter V, applicable from 2 August 2025) requires providers of General-Purpose AI models to disclose energy consumption data in technical documentation. For models designated as presenting systemic risk, energy efficiency must be formally assessed.
The European Commission is also mandated to publish periodic progress reports on standards for energy-efficient GPAI model deployment, with the first due in August 2028, and the possibility of recommending binding corrective measures thereafter. This is not yet a carbon budget — but it establishes the legal infrastructure for accountability.
Where Regolo fits in this picture
The paradox described above is not a reason to stop building AI. It is a reason to be intentional about where and how we build it — and to hold providers accountable for the infrastructure choices they make.
Our infrastructure is ISO 14001 certified, a standard focused on the continuous improvement of environmental management systems. We are qualified supporters of the Green Web Foundation, part of a network committed to making the web fully sustainable. We adhere to the EU’s DNSH (Do No Significant Harm) principle, ensuring that none of our activities cause significant harm to any environmental objective.
Our GPU run on 100% renewable energy sources, meaning every token generated, every inference request served, carries zero additional CO₂ emissions during operation.
Wth all computation remaining in European jurisdiction, we also answer the governance dimension of the paradox – teams concerned about data sovereignty, GDPR compliance, and EU AI Act alignment can run AI workloads without routing data through non-European infrastructure or trusting opaque offshore providers.
We operate with zero data retention at the inference layer — requests are processed and discarded, not stored, logged, or used for model training.
FAQ
Does running inference on renewable energy actually matter if the grid is still partly fossil-fueled?
Yes, in a meaningful way. When a data center purchases and consumes renewable electricity, it increases demand for clean generation and reduces the proportion of fossil-fuel electricity dispatched to the grid. Over time, this demand signal contributes to grid decarbonization. Running on 100% renewable energy at the provider level is the most direct mechanism currently available for eliminating operational carbon from AI inference.
Is inference really a bigger environmental problem than training?
For most deployed models, yes — and the gap widens over time. Training is a one-time cost; inference accumulates with every user request. Research indicates inference may account for 65–90% of a model’s total operational carbon over its commercial life. This is why the infrastructure decisions of inference providers — not just model developers — are central to the sustainability of AI.
What does quantization actually cost in terms of quality?
It depends on the task. For mathematical reasoning and complex multi-step inference, aggressive quantization (q3 and below) can meaningfully degrade output quality. For most conversational, summarization, classification, and code-assistance tasks, 8-bit and 4-bit quantized models deliver competitive accuracy with dramatically lower energy consumption. Evaluating quality-efficiency tradeoffs on your specific use case is always worth doing before committing to a model variant.
Does the EU AI Act address environmental impact directly?
The current AI Act (Chapter V, applicable from August 2025) requires GPAI model providers to disclose energy consumption data and, for high-risk systemic models, to formally assess energy efficiency. It does not yet set binding energy limits, but the Commission is required to periodically assess whether binding measures are necessary — meaning the regulatory floor may rise. Providers who document and demonstrate low-energy practices now will be better positioned as this framework matures.
How does serverless GPU inference reduce environmental impact compared to dedicated infrastructure?
Serverless inference means compute resources are allocated on demand and released when not in use — scale-to-zero. This eliminates the idle power consumption that makes dedicated or always-on GPU servers inefficient. When combined with renewable energy and carbon-aware scheduling, serverless architectures can deliver the same inference throughput with significantly lower total energy consumption.
What makes European data center jurisdiction relevant to sustainability?
European data center regulation is increasingly tightening requirements on energy efficiency, water use, and emissions reporting for digital infrastructure. By staying within this jurisdiction, providers are subject to an evolving set of environmental standards — and teams using those providers can rely on that accountability framework rather than having to audit it themselves. For teams subject to GDPR and the EU AI Act, this also eliminates cross-border data flows and simplifies compliance.
Start your free 30-day trial at regolo.ai and deploy LLMs with complete privacy by design.
👉 Talk with our Engineers or Start your 30 days free →
- Discord – Share your thoughts
- GitHub Repo – Code of blog articles ready to start
- Follow Us on X @regolo_ai
- Open discussion on our Subreddit Community
Built with ❤️ by the Regolo team. Questions? regolo.ai/contact or chat with us on Discord