Intelligent OCR uses vision-language models for accurate text extraction from complex documents like PDFs with tables, formulas, and mixed layouts. In 2026, DeepSeek-OCR-2 vs GLM-OCR vs PaddleOCR leads this space on OmniDocBench v1.5, a key benchmark for real-world parsing. These models handle distortions, multilingual text, and structured elements better than traditional OCR.
Model Specifications
DeepSeek-OCR-2
DeepSeek-OCR-2, released January 2026, features a 3-billion-parameter architecture with visual causal flow for token compression. It processes complex pages using 256-1,120 tokens, enabling 200,000 pages per day on an A100 GPU. Trained on 30 million PDF pages across 100 languages, including synthetic charts and formulas.
GLM-OCR
GLM-OCR is a lightweight 0.9-billion-parameter model under Apache-2.0 license. It excels in bulk processing at 1.86 PDF pages per second and 0.67 images per second. The three-stage pipeline supports tables, formulas, and seals in research or finance workflows.
PaddleOCR-VL-1.5
PaddleOCR-VL-1.5 from Baidu supports 100+ languages and handles skewed, warped scans, and lighting variations. It uses a 0.9-billion-parameter design for high-precision parsing of text, tables, formulas, and charts. The toolkit bridges images/PDFs to structured data for LLMs.
2026 Benchmark Comparison
DeepSeek-OCR-2 vs GLM-OCR vs PaddleOCR performance centers on OmniDocBench v1.5, evaluating overall accuracy, text, formulas, tables, and reading order
| Metric | DeepSeek-OCR-2 | GLM-OCR | PaddleOCR-VL-1.5 |
|---|---|---|---|
| OmniDocBench v1.5 (%) | 91.09 | 94.62 | 94.5 |
| Parameters (B) | 3 | 0.9 | 0.9 |
| PDF Throughput (pages/s) | High (200k/day A100) | 1.86 | Moderate |
| Token Efficiency | 10x compression 97% | N/A | Strong in layouts |
| Strengths | Compression, multilingual | Speed, SOTA score | Real-world distortions |
GLM-OCR holds the top OmniDocBench v1.5 score, followed closely by PaddleOCR-VL-1.5; DeepSeek-OCR-2 prioritizes efficiency. User tests rank GLM-OCR > PaddleOCR-1.5 > DeepSeek-OCR-2 for handwriting.
Key Differences
DeepSeek-OCR-2 stands out in visual token compression, retaining 97% accuracy at 10x reduction on Fox benchmark versus competitors needing 1,500-6,000 tokens. GLM-OCR and PaddleOCR-VL-1.5 match on size but lead in raw accuracy for formulas and tables. PaddleOCR excels in irregular layouts like vertical text and distortions, where DeepSeek may falter on order.
Implementation Steps
Install Dependencies
All models require Python 3.10+ and NVIDIA GPUs for best results
pip install torch transformers pillow
# For PaddleOCR: pip install paddlepaddle paddleocrCode language: PHP (php)DeepSeek-OCR-2 Usage
Load via Hugging Face Transformers for image-to-text extraction.
from transformers import AutoProcessor, AutoModelForVision2Seq
import torch
from PIL import Image
model_id = "deepseek-ai/DeepSeek-OCR-2"
processor = AutoProcessor.from_pretrained(model_id)
model = AutoModelForVision2Seq.from_pretrained(model_id, torch_dtype=torch.bfloat16).to("cuda")
image = Image.open("document.jpg")
inputs = processor(images=image, text="Extract text from this document.", return_tensors="pt").to("cuda")
generated_ids = model.generate(**inputs, max_new_tokens=1024)
text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(text)Code language: Python (python)Supports 100-token pages for efficiency.
GLM-OCR Usage
Run via Ollama or vLLM for fast inference.
ollama run glm-ocr "Parse this PDF: [upload path]"Code language: Shell Session (shell)Or SDK for batch: achieves 1.86 pages/second on PDFs.
PaddleOCR-VL Usage
Install PaddlePaddle then infer on multilingual docs.
from paddleocr import PaddleOCR
ocr = PaddleOCR(use_angle_cls=True, lang='en', use_gpu=True)
result = ocr.ocr('document.png', cls=True)
for line in result:
print(line)Code language: PHP (php)Handles 100+ languages and real-world scenarios.
Practical Use Cases
Use GLM-OCR for high-accuracy bulk finance docs; PaddleOCR-VL-1.5 for scanned archives with distortions. DeepSeek-OCR-2 fits large-scale processing needing low tokens, like 200k pages daily. Integrate via pipelines: preprocess → OCR → post-process with LLMs.
When to Choose Each
- GLM-OCR: Top benchmark score, fastest open model (94.62% OmniDocBench).
- PaddleOCR-VL-1.5: Robust for messy inputs (94.5%), multilingual.
- DeepSeek-OCR-2: Efficiency-focused (91.09%, token compression).
Test on your datasets, as real-world varies by layout complexity, but consider if your local GPU have the minimum requirements:
DeepSeek-OCR-2 Requirements
A 3B-parameter model needs at least 16 GB VRAM for standard inference, with 24 GB recommended for complex documents. Quantized versions (Q4) drop to 2 GB VRAM, Q8 to 4 GB, and FP16 to 7 GB; pair with 32 GB system RAM. RTX 4090 or equivalent suffices; CPU-only is possible but slow.
GLM-OCR Requirements
This 0.9B model runs inference on 8 GB VRAM GPUs, adjusting utilization if memory is tight. LoRA fine-tuning fits single 8 GB GPU; full tuning needs 24 GB. System RAM: 16-32 GB; supports vLLM for efficiency.
PaddleOCR-VL Requirements
Compact design enables CPU inference or low-end GPUs (4-8 GB VRAM implied by lightweight VLM). No strict VRAM minimum listed, but runs on servers, mobiles, and embedded devices with PaddlePaddle. Recommend 16 GB RAM; GPU accelerates multilingual batches.
Comparison Table
| Model | Min VRAM (Inference) | Min RAM | GPU Example | CPU Support |
|---|---|---|---|---|
| DeepSeek-OCR-2 | 16 GB (FP16), 2 GB (Q4) | 32 GB | RTX 4090 | Yes, slow |
| GLM-OCR | 8 GB | 16 GB | Any 8 GB NVIDIA | Partial |
| PaddleOCR-VL | 4-8 GB | 16 GB | Consumer GPU | Full |
Benchmarks
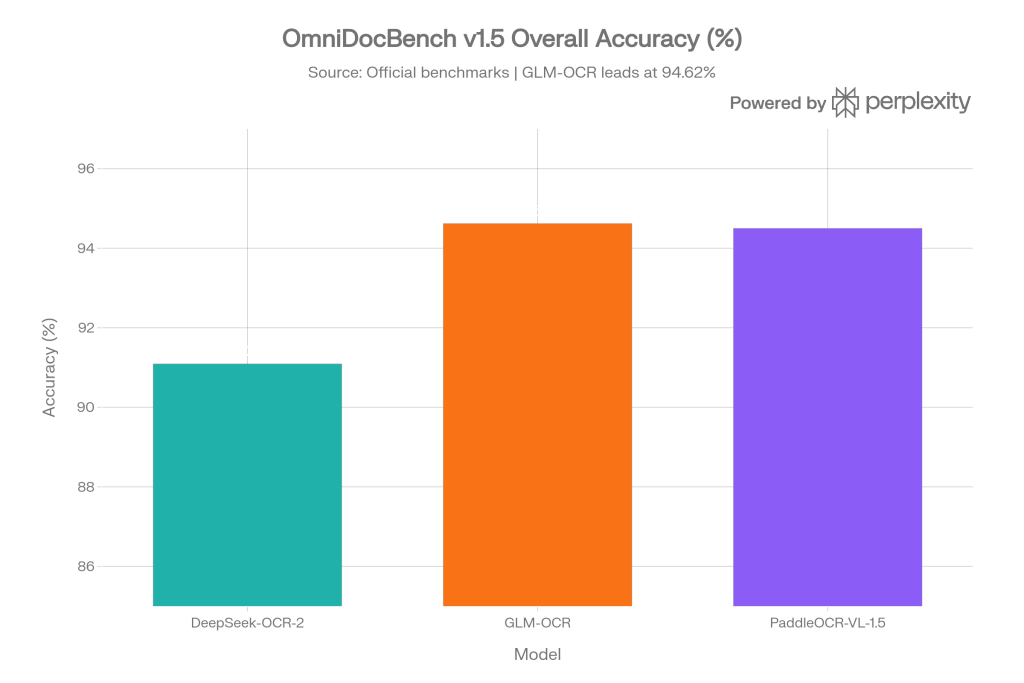
OmniDocBench v1.5 Overall Accuracy
This chart compares the headline benchmark scores across all three models. GLM-OCR leads at 94.62%, followed closely by PaddleOCR-VL-1.5 at 94.50%, with DeepSeek-OCR-2 at 91.09%.
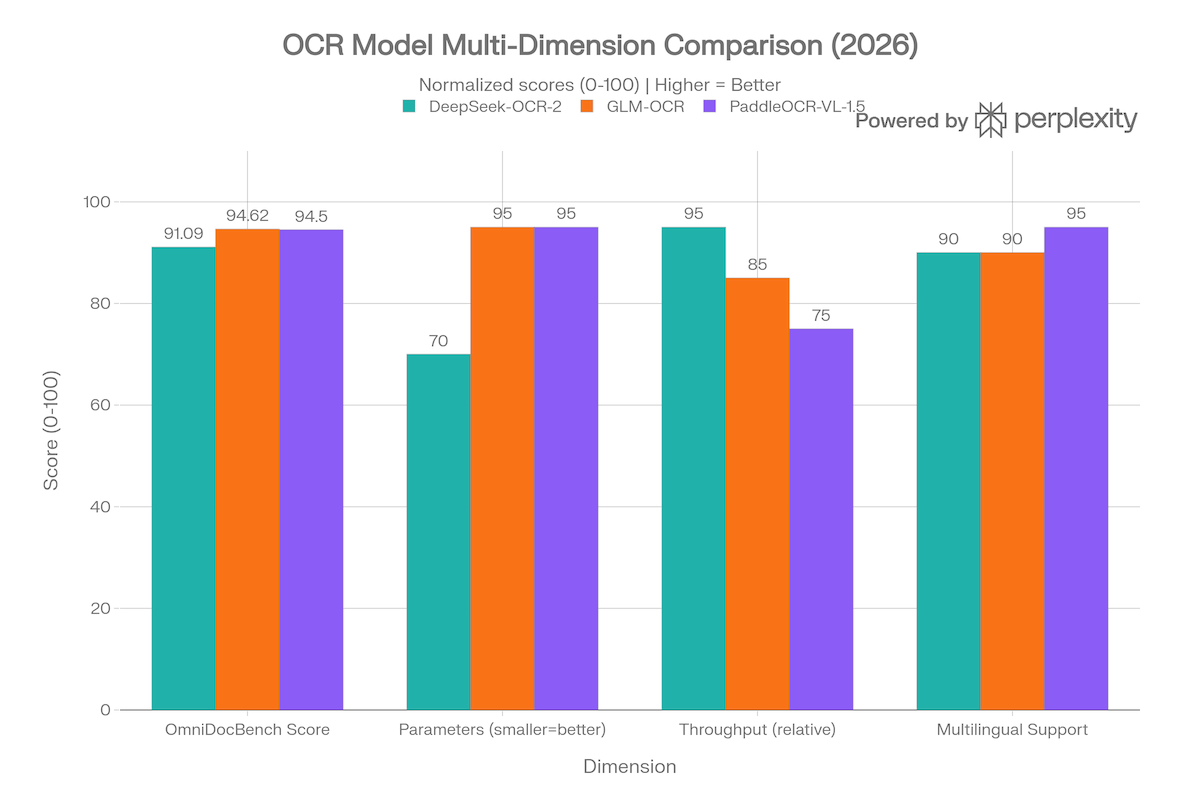
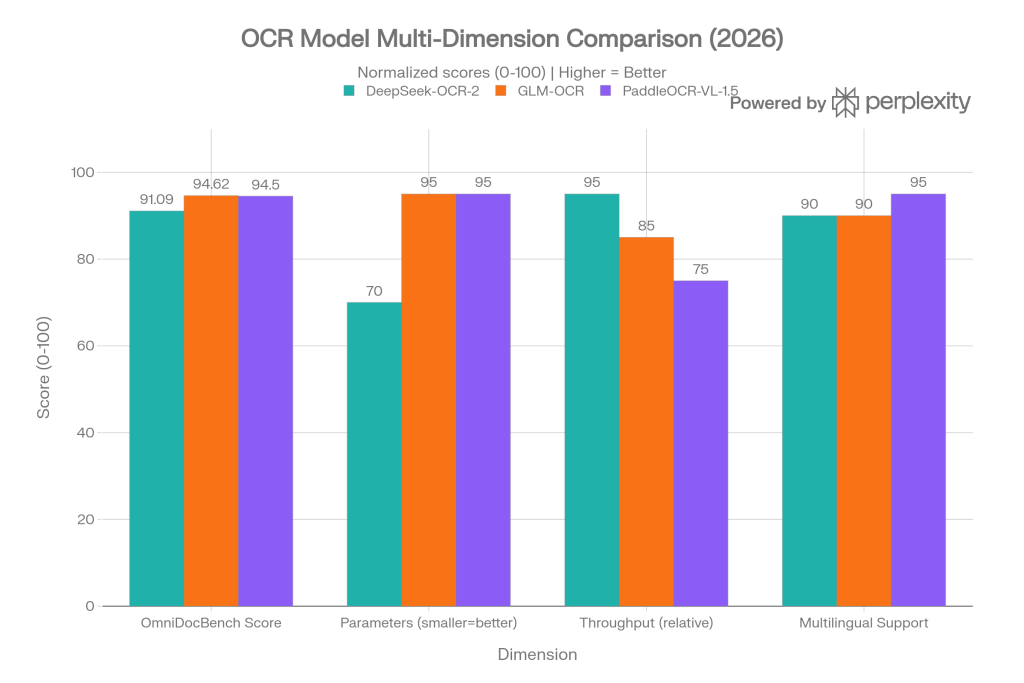
Multi-Dimension Comparison
This grouped bar chart normalizes four key dimensions (0–100 scale, higher = better) to give a fuller picture beyond raw accuracy:
- OmniDocBench Score: actual accuracy percentages from official benchmarks
- Parameters (smaller = better): GLM-OCR and PaddleOCR-VL-1.5 score higher at 0.9B vs DeepSeek-OCR-2’s 3B
- Throughput (relative): DeepSeek-OCR-2 leads with 200k pages/day on A100; GLM-OCR achieves 1.86 pages/s for real-time use
- Multilingual Support: PaddleOCR-VL-1.5 edges ahead with 100+ languages including rare scripts like Tibetan and Bengali
👉 Sign Up and start using OCR models for Free →
- Regolo Discord – Share your thoughts
- GitHub Repo – Code of blog articles ready to start
- Follow Us on X @regolo_ai
- Open discussion on our Subreddit Community
🚀 Ready to scale?
Built with ❤️ by the Regolo team. Questions? support@regolo.ai or chat with us on Discord