
As generative AI applications move from fragile prototypes to high-scale production systems, the operational costs of LLM API calls can quickly spiral out of control. Managing API keys, handling rate limits, caching repetitive queries, and implementing fallback routines are challenges every engineering team must eventually face.
Rather than presenting a standard, feature-by-feature benchmark, this article offers a high-level overview of how to think about cost optimization. To illustrate this, we have selected three of the most interesting and diverse tools we’ve come across recently:
Bifrost, Requesty, and Portkey: because each operates in a fundamentally different way, looking at them together provides a perfect map of the different paths you can take to optimize your LLM stack.
Architectural Reality Check: Apples, Oranges, and Go Proxies
To understand why a simple comparison doesn’t do these tools justice, we must look at the completely different paradigms they represent:
- Bifrost is a Network-Level Reverse Proxy (Self-Hosted Go Binary). It acts as a lightweight, local router that optimizes the infrastructure and latency layer. It resides directly inside your cluster with a near-zero footprint, routing traffic to private models.
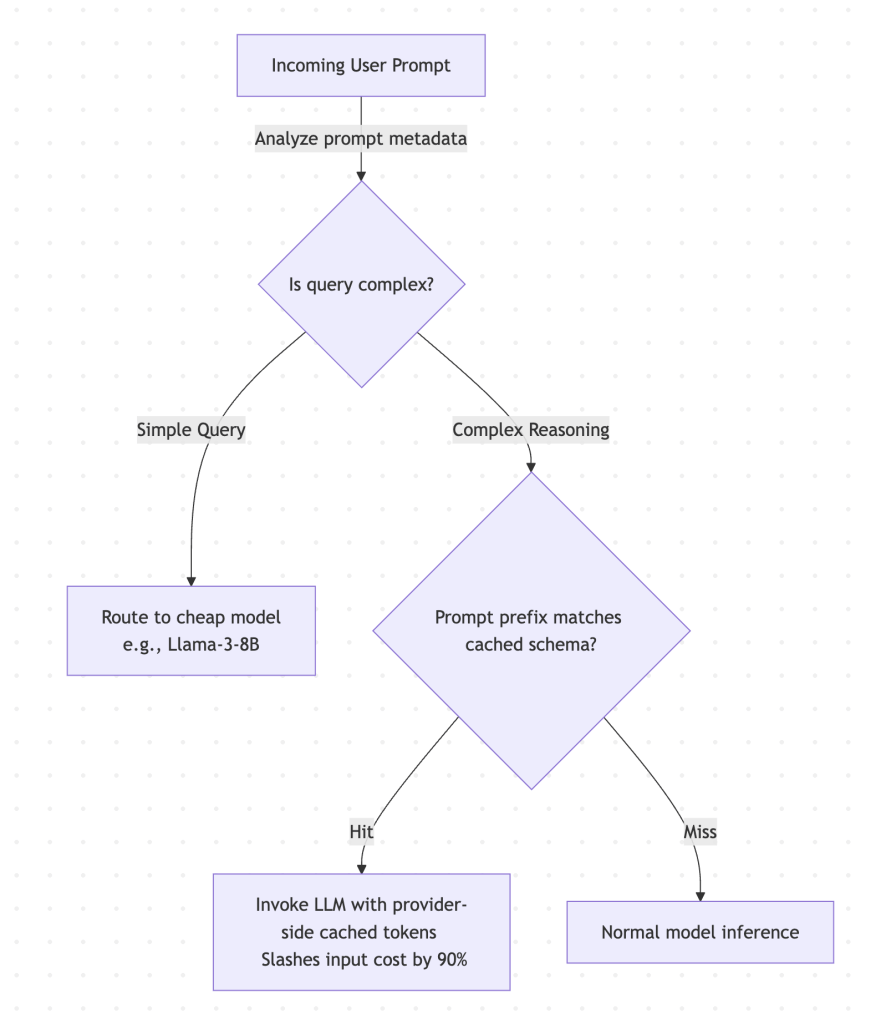
- Requesty is an API Broker & Managed SaaS Router. It optimizes the commercial billing layer. It sits in the cloud between your app and commercial API providers, dynamically switching models and using prompt caching to cut down your external bills.
- Portkey is an Enterprise LLMOps Control Plane. It is a full developer governance suite. Its gateway layer is designed to feed rich telemetry data to a central system that manages prompts, redacts PII, and enforces organization-wide budget quotas.
This guide is not about picking a “winner” – Instead, it is a bird’s-eye view of how these distinct approaches work, helping you decide which optimization pattern fits your team’s specific goals.
Table of Contents
- The shift from prompt engineering to loop engineering
- Three distinct paths to cost and token optimization
- Gateway optimization pipelines compared
- Exploring the three tools
- Where to position each product in your stack
- Exploring the three tools
- Where to position each product in your stack
- When you use an AI gateway, you must carefully evaluate its network path
- European data sovereignty and the Regolo.ai integration
- FAQs
The shift from prompt engineering to loop engineering
Today, the industry is moving rapidly toward Loop Engineering—designing systems around autonomous feedback loops where models analyze, plan, execute, verify, and iterate on tasks without human intervention.

In an agentic loop, a single user request can trigger dozens of internal LLM calls: the agent might call a small model to classify an intent, use a mid-sized model to draft code, run a validation suite, and then call a larger frontier model to self-correct any errors.
Under a Loop Engineering paradigm, an LLM gateway is not just a convenience—it is a critical necessity.
The gateway must cache intermediate steps, route simpler sub-tasks to cheaper models, handle sudden rate limits gracefully, and log every step for auditing.
Three distinct paths to cost and token optimization
To evaluate how these three approaches help optimize your stack, we must look beyond superficial comparisons and understand how they manage actual model expenses, resource footprint, and budget leaks.
Token optimization and caching strategies
Reducing the number of tokens sent to and received from LLM providers is the single most effective way to lower your bill.
- Requesty offers highly advanced prompt caching that promises up to a 90% reduction in input token costs for repetitive contexts: It automatically identifies static prefixes (such as long system prompts, database schemas, or agent context) and caches them on the provider side where supported, or manages an exact-match cache to bypass the model entirely.
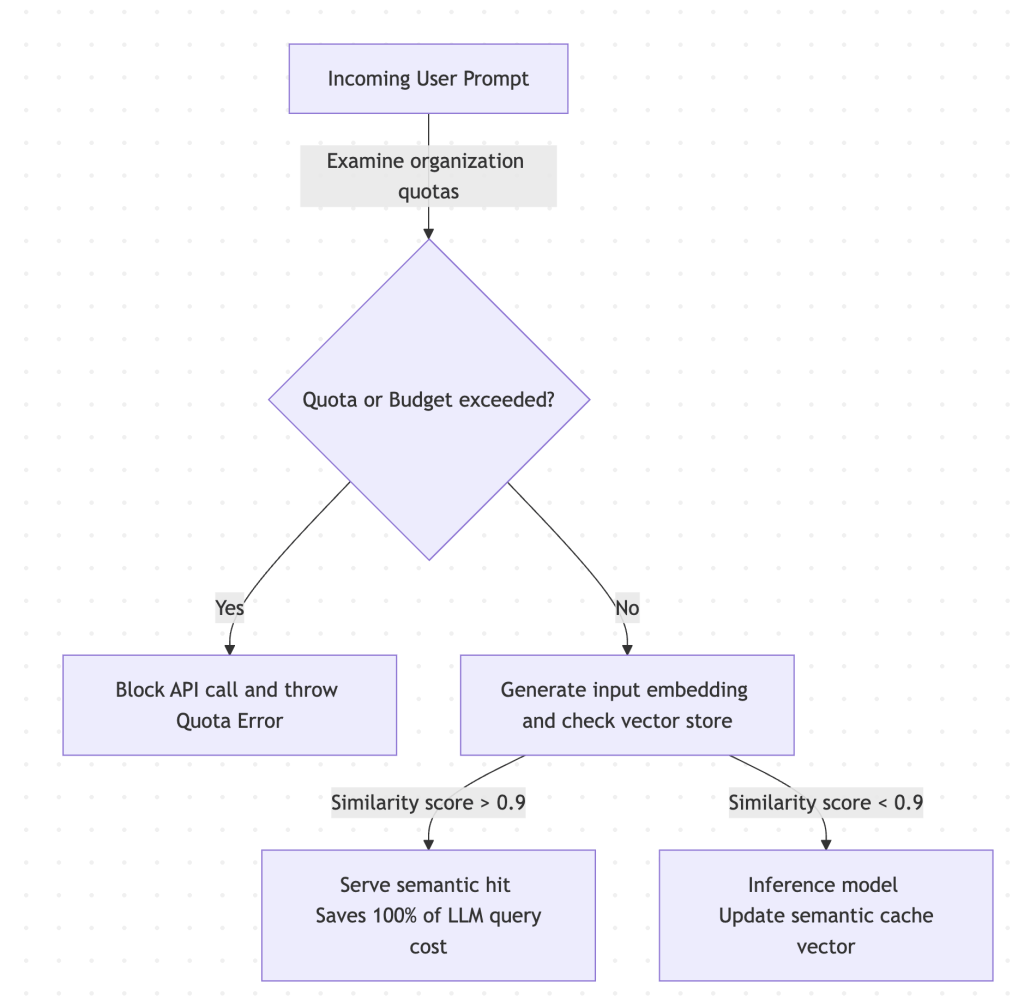
- Portkey specializes in semantic caching. Instead of requiring an exact match, Portkey uses vector embeddings to identify queries with identical meanings. For example, if one user asks “How do I reset my password?” and another asks “Password reset instructions,” Portkey serves the cached response without calling the LLM, saving 100% of the query tokens.
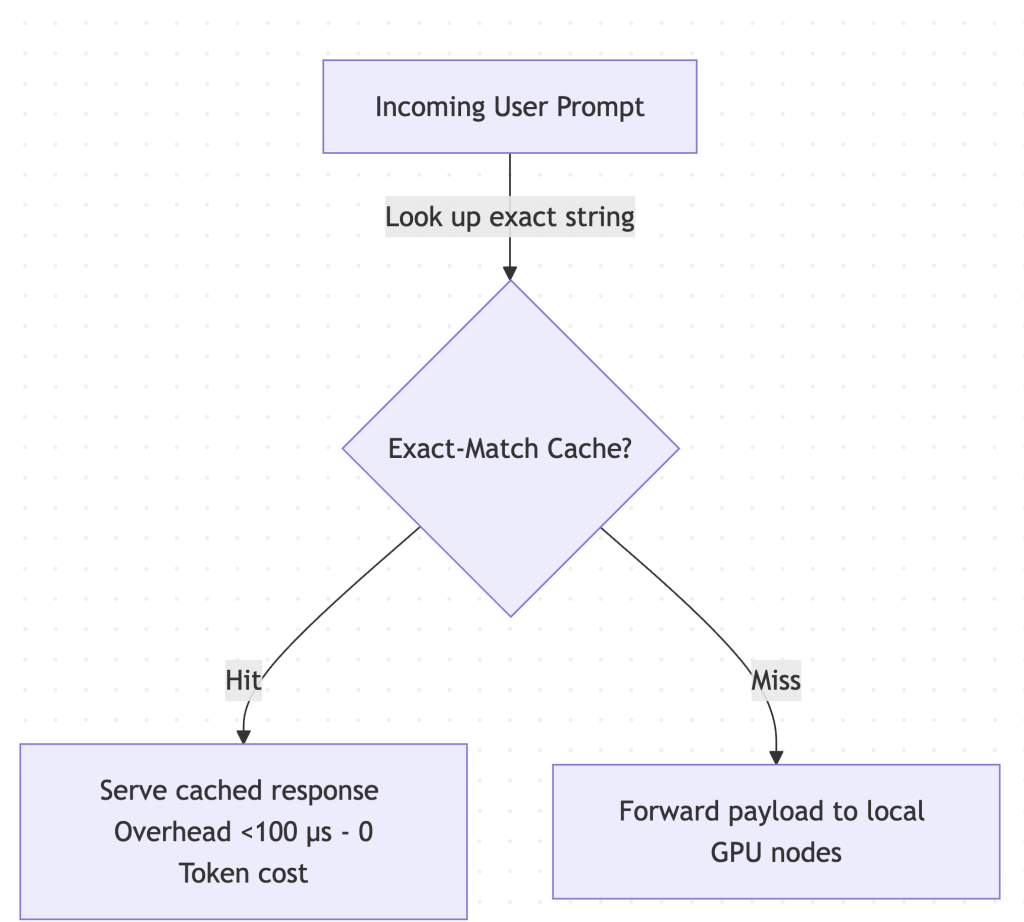
- Bifrost provides basic, high-speed exact-match caching via in-memory storage or a local Redis instance. While it lacks semantic understanding, its cache lookups complete in microseconds, making it perfect for caching high-frequency, standardized API lookups.
Memory and infrastructure overhead
When running gateways in production, the memory footprint and latency overhead of the gateway itself must be factored into your operational costs.
- Bifrost is written in Go and compiles to a single native binary. It has near-zero memory overhead (often utilizing less than 50MB of RAM even under heavy load) and adds less than 100 microseconds of network transit time. This allows you to host it on tiny, inexpensive virtual machines right next to your application services.
- Requesty operates as a managed SaaS, meaning you pay zero local memory or CPU costs. However, every request must travel to Requesty’s cloud servers before reaching the model provider. This adds a slight network latency penalty depending on the geographic location of your servers, though they mitigate this for European buyers with their dedicated EU router.
- Portkey offers an open-source TypeScript gateway that can be self-hosted. While Node.js/TypeScript environments consume slightly more memory than Go-compiled binaries, Portkey’s resource footprint is highly predictable. Their hybrid model allows you to run the lightweight gateway locally while offloading heavy logging and dashboard analytics to their cloud control plane.
Budget caps and runaway loop protection
Autonomous agent loops can easily get stuck in infinite execution cycles, spending thousands of dollars in minutes if left unchecked.
- Portkey provides the most advanced guardrails for this scenario. It allows you to set strict budget limits and token quotas at the organization, team, or individual API key level. If an agent goes rogue, Portkey immediately blocks further API calls.
- Requesty includes robust budget limits and automatic failover structures. If a cheap model fails, it transitions up the model tier gracefully, but you can configure hard spending caps to prevent unexpected bills.
- Bifrost relies on standard network rate-limiting. It protects your infrastructure from being overwhelmed by too many rapid requests, but lacks the user-level financial auditing dashboards found in Portkey and Requesty.
Exploring the three tools
Bifrost: the self-hosted speed demon
Acts as a lightweight reverse proxy that sits directly in front of your LLM endpoints.
- Key Strengths: It supports cluster mode natively, allowing you to scale your gateway horizontally across Kubernetes pods. It includes an adaptive load balancer that shifts traffic away from failing endpoints based on real-time latency feedback.
- When to Use It: choose Bifrost if you are building high-throughput, low-latency applications where every microsecond matters. It is the ideal candidate for teams that want a 100% self-hosted setup inside their own private network to ensure complete data control without paying external SaaS markups or licensing fees.
Requesty: the cost-optimizing dynamic router
It acts as an intelligent proxy layer supporting over 400 models across 30+ providers through a unified, OpenAI-compatible endpoint.
- Key Strengths: requesty excels at fallback chains and automated failover. If your primary provider rate-limits you or goes down, Requesty immediately routes the request to an equivalent model on a secondary provider.
- When to Use It: if you want to minimize model expenses without building custom routing logic, and If your application experiences highly variable traffic or requires multi-provider redundancy with zero engineering overhead, Requesty offers a quick, cloud-managed solution.
Portkey: the enterprise control plane and observability suite
It’s an end-to-end LLMOps infrastructure platform, Its status as an industry standard for securing and governing AI workloads is highly recognized.
- Key Strengths: Portkey gives you deep tracing of agent workflows, showing you exactly how tokens, latency, and costs break down across complex multi-step chains.
It includes a built-in Prompt Registry, enabling teams to version, test, and update prompts dynamically on the server without redeploying backend code. - When to Use It: it’s the clear choice for enterprise teams that require strict auditing, security compliance (HIPAA, SOC2, GDPR), and centralized prompt management.
Where to position each product in your stack
Understanding where to deploy and position these gateways is crucial for maintaining low latency and secure boundaries.
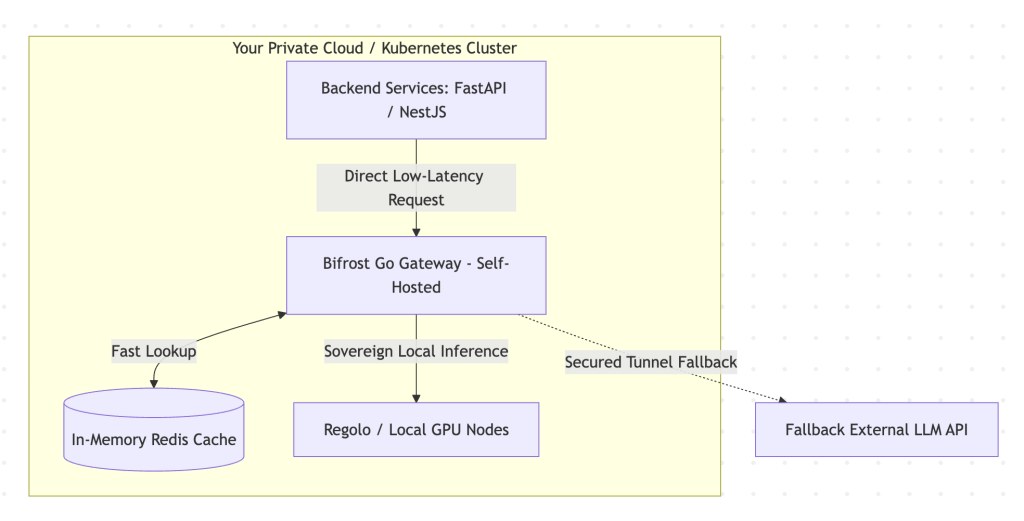
Bifrost positioning
Bifrost is deployed internally within your local network or virtual private cloud (VPC). It sits directly between your backend services (FastAPI, NestJS) and your local or private European inference servers.
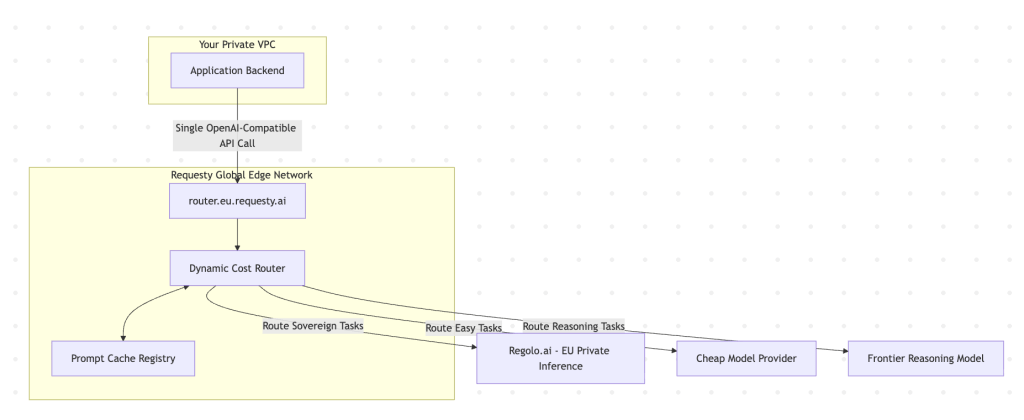
Requesty positioning
Requesty is positioned as an edge proxy. Your backend services point to Requesty’s secure cloud servers, which evaluate the incoming query and dynamically route it across various external model providers to find the most cost-effective path.
Portkey positioning
Portkey is deployed in a hybrid model. You run Portkey’s lightweight, open-source gateway inside your own local network to execute real-time guardrails and check the local cache. The gateway then forwards non-sensitive logging metadata and execution traces to Portkey’s secure cloud dashboard for analysis.
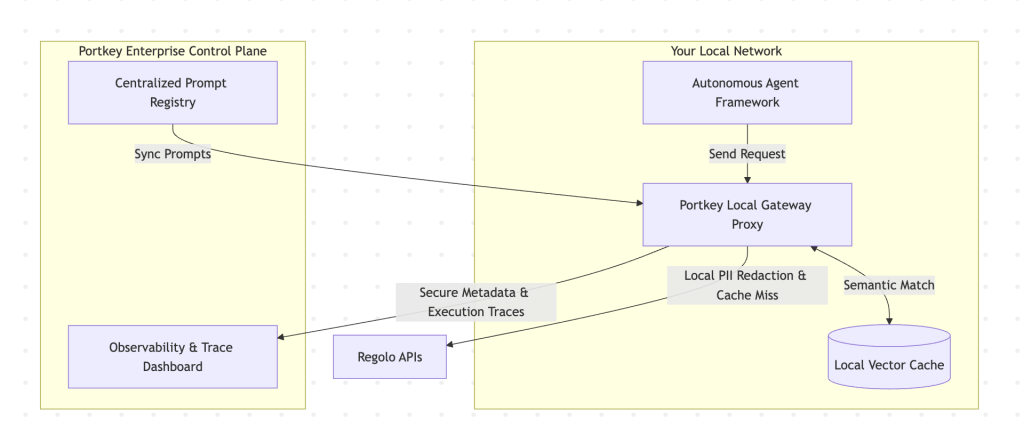
When you use an AI gateway, you must carefully evaluate its network path
- If you choose Portkey: you can self-host their open-source gateway within your local European cloud while sending non-sensitive metadata to their SaaS control plane, or utilize their enterprise single-tenant deployments.
- If you choose Requesty: you should configure your applications to point explicitly to
router.eu.requesty.ai, ensuring that all request payload processing remains within the EU.
- If you choose Bifrost: you get immediate, absolute sovereignty. Because Bifrost is written in Go and completely open-source, you can deploy it in your own European private cloud as a self-hosted cluster.
FAQs
Which gateway provides the absolute best token savings?
If your application handles highly repetitive queries (such as customer support), Portkey’s semantic caching provides the highest token savings by avoiding model calls for similar meanings. If your application runs complex multi-step agent loops with long system prompts, Requesty’s automated prompt caching provides superior savings.
Is Bifrost difficult to manage compared to SaaS gateways?
Because Bifrost is a self-hosted Go binary, it requires basic server maintenance, monitoring, and container configuration (Docker/Kubernetes). However, it rewards you with zero subscription fees, absolute data privacy, and sub-millisecond local network latency.
How do gateways help debug runaway costs in agentic loops?
Gateways log every transaction in a multi-step execution chain, allowing you to trace exactly which step of an autonomous loop triggered a costly LLM call. Portkey, for instance, allows you to visualize entire trace trees to pinpoint where a prompt became bloated or where an agent became stuck in an infinite loop.
Start your free 30-day trial at regolo.ai and deploy LLMs with complete privacy by design.
👉 Talk with our Engineers or Start your 30 days free →
- Discord – Share your thoughts
- GitHub Repo – Code of blog articles ready to start
- Follow Us on X @regolo_ai
- Open discussion on our Subreddit Community
- Full list of model available: Models
Built with ❤️ by the Regolo team. Questions? regolo.ai/contact or chat with us on Discord