
The decision of where to execute your large language models is no longer just an infrastructure line item; it is a core architectural and legal choice that impacts every layer of your application. Every prompt your system evaluates contains proprietary IP, customer records, or operational data; understanding how an inference provider manages these payloads is the first step toward building compliant, cost-effective AI systems.
Developers of high-risk agentic systems must implement full execution tracing, continuous evaluation across security and bias dimensions, and hard-coded human intervention mechanisms inside their agent graphs.
The foundation of this compliant architecture is a sovereign European inference provider: this ensures that raw data payloads are processed locally under EU jurisdiction with zero data retention, mitigating the severe regulatory risks of international transfers under the US Cloud Act.
Table of contents
- The EU AI Act: what it requires for autonomous systems
- Observability and tracing: capturing multi-step agent execution
- Continuous evaluation: safety, quality, and adversarial resilience
- Human oversight: embedding intervention in the agent graph
- The infrastructure foundation: why your inference provider is your first line of compliance
- Article crosswalk: mapping regulatory requirements to engineering capabilities
- The compliance roadmap: where to start before August 2026
- FAQ
The EU AI Act: what it requires for autonomous systems
The EU AI Act stands as the first comprehensive regulatory framework for artificial intelligence, establishing clear categories of risk and imposing strict operational duties on systems deemed high-risk. If your team is deploying agents in critical sectors—such as financial credit scoring, HR recruitment, medical devices, law enforcement, or critical infrastructure—the compliance clock is winding down; non-compliance with these provisions carries severe financial penalties reaching up to €15 million or 3% of worldwide annual turnover.
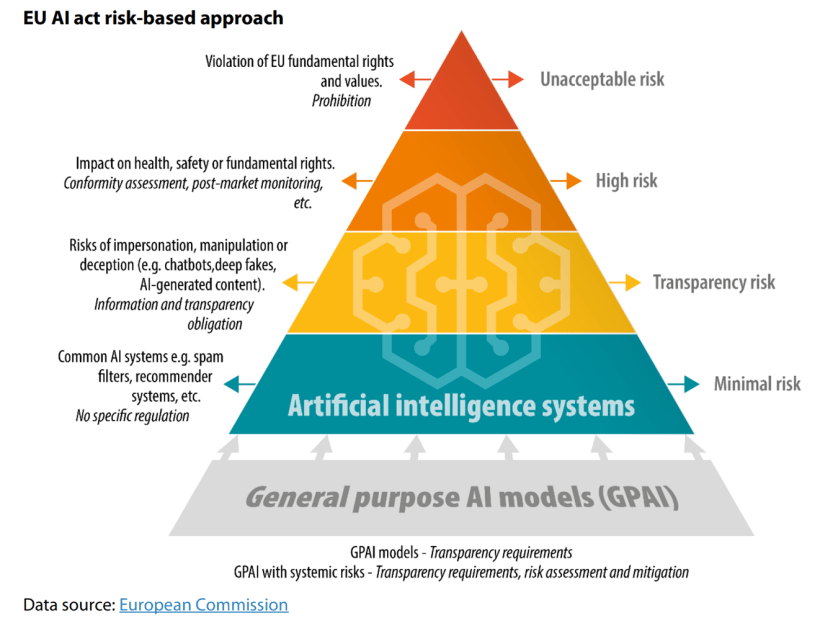
Traditional static software compliance models fail when applied to modern AI agents: these systems do not follow predictable, deterministic code paths; instead, they generate plans dynamically, retrieve external context, and call third-party APIs based on their own internal reasoning loops. The Act recognizes this complexity by requiring five primary operational safeguards:
- a living risk management system: a continuous protocol that spans the entire development lifecycle, running from early training datasets to live production environments.
- automatic event logging: the persistent capture of system actions over its lifetime to support post-market monitoring and facilitate immediate incident detection.
- built-in transparency: clear mechanisms to ensure model decisions, retrieved contexts, and outputs are interpretable by human operators.
- guaranteed human oversight: concrete interface controls that allow humans to intervene, override, or interrupt the system at any point in its execution.
- post-market monitoring: a continuous operational pipeline to evaluate live performance, track drift, and report compliance anomalies in real time.
For developers of agentic systems, meeting these criteria means implementing technical tracing and evaluation frameworks directly into the execution pipelines; standard policy papers and static audits are no longer sufficient to prove compliance during a regulatory audit.
Observability and tracing: capturing multi-step agent execution
When an agent takes a series of autonomous actions—such as query planning, searching a database, generating a tool payload, and executing a write operation—regulators require a complete, chronological record of that decision thread. Under Articles 12 and 13, decisions must be traceable and interpretable; this is a task that cannot be solved by simple application logs or unstructured stdout print statements.
To construct a compliant audit trail, your tracing framework must capture the full execution graph of every single run:
- inputs and outputs of every node: logging the raw prompt payloads and model completions at every step of a multi-turn conversation.
- tool invocations and responses: capturing the exact arguments passed to external APIs along with the raw data returned to the model.
- state transitions: recording how the agent’s internal memory state changes after each step, providing a clear explanation of why an agent decided to transition from planning to execution.
- structured metadata: attaching timestamps, user IDs, and model parameters to every trace to enable rapid search and filtering during post-market audits.
By visualizing these runs through specialized tools like LangSmith Studio or integrated open-source tracing dashboards, developers can reconstruct the precise context of any failure: this turns what would otherwise be a black-box system into an auditable, transparent pipeline.
Continuous evaluation: safety, quality, and adversarial resilience
Article 15 of the Act requires high-risk systems to declare accuracy metrics, prove adversarial resilience, and defend against common attack surfaces; because user prompts and retrieved contexts are unpredictable, static test suites are insufficient to verify a live system. You must establish online evaluation pipelines that run on production traffic: these continuously sample live traces and score them against specific compliance dimensions.
These evaluation layers must cover three critical compliance areas:
1. Fairness and safety
- bias detection: evaluators must check completions for discriminatory language or skewed outputs related to race, gender, age, or religion.
- toxicity scoring: automatic filters must identify hostile, offensive, or inappropriate language before it reaches end users.
- PII leakage prevention: scanners must flag accidental exposure of sensitive personal data—such as phone numbers, emails, or government IDs—contained in prompts or model outputs.
2. Accuracy and quality
- hallucination metrics: checking whether generated outputs are grounded in retrieved documents or if they introduce unverified, fabricated facts.
- answer relevance: scoring how well the agent’s response aligns with the user’s original query, helping to identify loops that have drifted off-topic.
- plan adherence: verifying that the agent followed its intended execution graph and did not bypass required security or validation nodes.
3. Adversarial resilience
- prompt injection detection: identifying malicious inputs designed to hijack the model’s system instructions.
- tool-calling validation: scoring the quality of tool selection to ensure the agent does not execute dangerous or unauthorized API payloads.
When these evaluations detect a violation—such as a hallucination score exceeding a critical threshold—your infrastructure must trigger automated alerts via webhooks or incident response systems to let operators mitigate the issue before it compounds.
Human oversight: embedding intervention in the agent graph
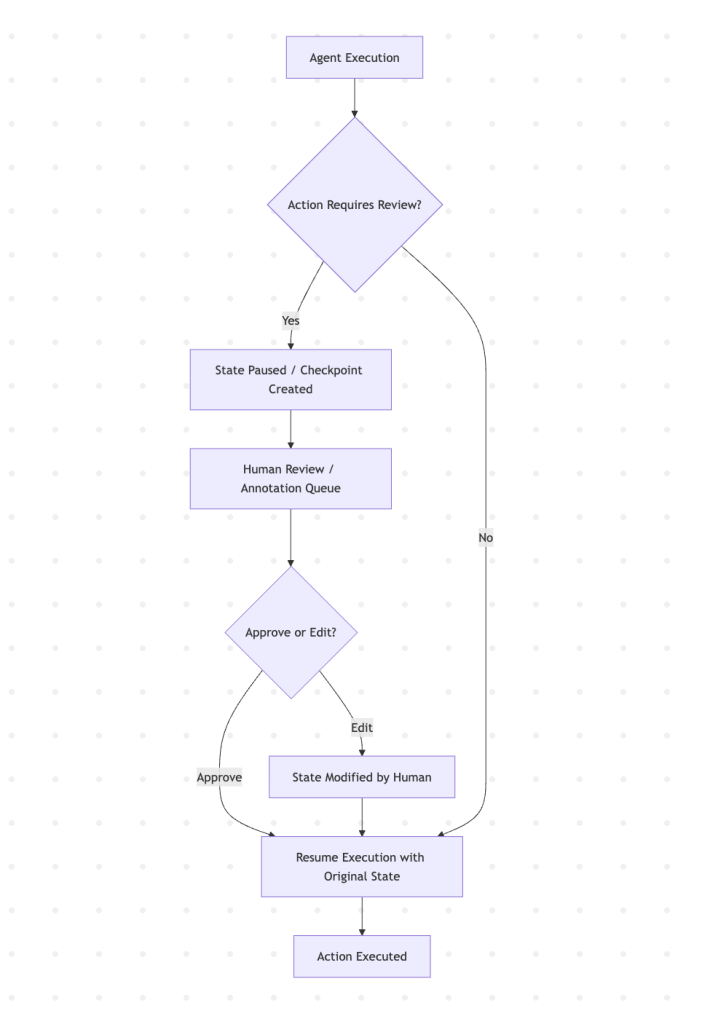
Article 14 establishes human oversight as a core architectural principle: humans must be capable of understanding, intervening on, overriding, and interrupting the AI system at any time during its operational lifecycle.
In practice, this means human-in-the-loop (HITL) cannot be an afterthought built onto the user interface; it must be an integrated primitive inside the agent’s state graph.
Using state-management runtimes like LangGraph, developers can implement this pattern natively:
- the interrupt primitive: the runtime automatically pauses execution before a sensitive node—such as a financial transaction or a database write—is executed.
- durable checkpointing: the agent’s entire memory state is saved to a persistent database, allowing the execution to wait indefinitely without consuming compute resources or losing state.
- annotation queues: the paused state is routed to a specialized dashboard where human reviewers can inspect the planned action, modify the proposed variables, and click “Resume” to send the modified state back to the agent.
- auditable feedback loops: the human intervention is recorded directly in the execution trace, providing clear, legally binding evidence that the required oversight took place before the action was finalized.
The infrastructure foundation: why your inference provider is your first line of compliance
All the tracing, evaluation, and human oversight layers are useless if the underlying model execution is fundamentally non-compliant. Under GDPR and the EU AI Act, where your data is processed and how it is stored are critical legal questions; this is where the choice of your inference provider becomes your first and most important architectural decision.
Let us compare the three primary deployment paths across the legal and operational parameters that govern European compliance:
| Compliance feature | US hyperscalers (e.g., OpenAI, Azure) | European inference providers (e.g., Regolo.ai) | Self-hosting (On-Prem / Private VPC) |
|---|---|---|---|
| Data residency | mixed: even if servers are physically in the EU, parent companies remain subject to the US Cloud Act | strictly EU-based: 100% of data processing and storage remains within EU borders | local: complete control over physical hardware location |
| Data retention | high risk: prompts are often stored for diagnostics, safety monitoring, or future model training | zero data retention: prompts are processed transiently in RAM and never written to disk | full control: logging policies are defined internally |
| GDPR compliance | complex: requires complex transfer agreements and carries inherent risks of transatlantic data leaks | native by design: fully aligned with Chapter V and GDPR Article 32 data protection rules | native: but requires massive internal legal and IT auditing overhead |
| Operational overhead | low: standard web API | low: standard OpenAI-compatible API (plug-and-play) | extremely high: requires dedicated team for scaling, GPU drivers, and container orchestration |
Under the US Cloud Act, any US-parented technology provider can be compelled by federal warrants to turn over data stored on their servers; this applies even if those servers are physically located in Frankfurt, Dublin, or Paris. This means that routing your agentic payloads through a US hyperscaler—even one using a European cloud region—exposes your organization to significant compliance liabilities.
By integrating a specialized European provider like Regolo.ai, you eliminate this risk. Your API calls go to high-performance, European-owned infrastructure that operates under strict zero-retention policies; your sensitive prompts, tool payloads, and system memories are processed in RAM and immediately discarded, ensuring your compliance trail remains clean and legally defensible.
Article crosswalk: mapping regulatory requirements to engineering capabilities
To help engineering teams map legal requirements directly to specific technical features, we have constructed a crosswalk that translates the EU AI Act articles into actionable development tasks:
| Article | Regulatory requirement | Technical implementation (Regolo + LangSmith/LangChain) |
|---|---|---|
| Art. 9 | risk management system throughout the entire lifecycle | continuous online monitoring, custom safety evaluators, and automated alert thresholds |
| Art. 10 | data governance, bias prevention, and dataset auditing | bias, fairness, and demographic safety evaluators running on live samples |
| Art. 12 | automatic event logging over the system’s operational lifetime | trace storage with timestamps, secure bulk export, and EU-only data residency |
| Art. 13 | transparency, interpretabilty, and output explanation | full reasoning traces, system prompts inspection, and visual execution graphs |
| Art. 14 | guaranteed human oversight and intervention capabilities | LangGraph interrupt primitives, checkpointing, and annotation review queues |
| Art. 15 | declared accuracy, adversarial resilience, and consistency | correctness scoring, adversarial injection evaluators, and plan adherence metrics |
| Art. 72 | post-market monitoring and active compliance reporting | drift detection, online evaluation dashboards, and direct webhook notifications |
The compliance roadmap: where to start before August 2026
If you are running high-risk autonomous systems, you cannot wait until August 2026 to begin auditing your pipelines; you should approach your implementation in four distinct phases:
- establish complete observability: integrate end-to-end tracing across your entire agent graph; every tool call, database query, and model completion must be recorded to build the compliance foundation.
- deploy online evaluators: configure automated safety scoring on a sample of your live production traffic; start with critical evaluators for bias, PII leakage, and hallucination.
- implement human-in-the-loop controls: embed LangGraph’s interrupt primitive before any high-risk action node; set up review queues to allow humans to modify states and audit every intervention.
- migrate to sovereign EU infrastructure: redirect your API endpoints from US-hosted hyperscalers to specialized European providers; by swapping your client base URL and API keys to Regolo.ai’s OpenAI-compatible EU endpoints, you instantly secure your data residency and satisfy international transfer restrictions.
Ultimately, complying with the EU AI Act is not just a regulatory burden: it is a set of best practices that align with high-quality software engineering; making your agents observable, predictable, and governable is simply how you build AI systems that work reliably in production.
Related resources
To explore these compliance and architectural topics further, we recommend reading our dedicated guides:
- How to Implement GDPR-Compliant AI Inference: a Pragmatic Framework – a technical blueprint for auditing your AI data pipelines.
- Data Privacy First: CTO Guide to AI Act Compliance – understanding the upcoming legal requirements for European AI deployments.
- Cloud LLM Hosting in Europe: Scalable, Private and Green – why our energy-efficient European infrastructure is both sustainable and secure.
- Checklist: Choosing an EU-Based LLM Provider in 2026 – a detailed comparison framework for evaluating privacy-focused vendors.
Ready to migrate your agentic infrastructure to a 100% compliant EU cloud? Explore Regolo.ai Pricing for transparent, pay-per-token pricing.
Apply for the Regolo Builder Program to receive free compute credits for your next deployment.
FAQs
How does the EU AI Act affect open-source AI models?
The EU AI Act provides certain exemptions for open-source models; however, if those models are integrated into a high-risk application (such as HR recruitment or financial credit scoring), the overall system remains subject to full compliance duties. This means you must still implement tracing, evaluations, and human oversight regardless of whether your underlying model is open-weights or proprietary.
Can I run compliant agent loops on US-hosted hyperscalers?
No: even if you implement perfect tracing and oversight, sending unencrypted EU user data to US-parented hyperscalers violates GDPR Chapter V transfer rules due to the US Cloud Act. A truly compliant setup requires both application-level governance and a sovereign European infrastructure layer.
How much latency does a human-in-the-loop interrupt add to my agent?
While human review pauses execution, the use of durable state checkpointing means your agent consumes zero compute or memory resources while waiting; the overall latency depends entirely on your review team’s response time, while the technical pause-and-resume lookup takes only milliseconds.
Do I need to audit my training datasets under the Act?
Yes: Article 10 requires strict data governance, bias examination, and safety auditing of datasets used to train or fine-tune models; if you use a pre-trained model on an inference provider, you should verify that the provider uses models trained on compliant, high-quality data.
Start your free 30-day trial at regolo.ai and deploy LLMs with complete privacy by design.
👉 Talk with our Engineers or Start your 30 days free →
- Discord – Share your thoughts
- GitHub Repo – Code of blog articles ready to start
- Follow Us on X @regolo_ai
- Open discussion on our Subreddit Community
Built with ❤️ by the Regolo team. Questions? regolo.ai/contact or chat with us on Discord