Many teams building production AI applications quickly realize that single-turn prompting inevitably falls apart when faced with intricate, open-ended tasks. We have spent the last few quarters auditing systems that break down under cumulative error, and the consensus is clear: static instructions are no longer sufficient.
This stateful project’s design is a direct, practical extension of Sakana AI’s Fugu, a pioneering evolutionary search framework for LLM agent loops that demonstrated how automated, cyclic agent workflows can outpace human-designed pipelines, achieving state-of-the-art benchmarks on challenging reasoning tasks without changing underlying model weights.
Validating the Thinker-Worker-Verifier pattern as a core stateful architecture, we are moving away from fragile prompt adjustments toward systematic, autonomous feedback loops.
How get better over time the agents
The Thinker-Worker-Verifier pattern is an advanced multi-agent architecture where a planning agent (Thinker) decomposes tasks, a specialized execution agent (Worker) generates outputs, and an evaluation agent (Verifier) validates quality, driving a structured iterative feedback loop.
Inspired by the evolutionary benchmarks of Sakana AI’s Fugu, this stateful cycle ensures that outputs are continuously refined, avoiding infinite loops through deterministic escalation policies like Retry, Reassign, and Replan. By grounding execution in a dedicated memory layer, this pattern transforms erratic LLM calls into predictable, self-correcting corporate systems.
Table of Contents
The shift from prompt adjustments to Loop Engineering
For years, the industry treated LLM application design as a linguistic exercise, this new approach was inherently limited because it ignored a basic principle of software engineering: complex systems require control structures, validation gates, and state management.
We advocate for a radical shift toward Loop Engineering instead of hoping a single, dense prompt will guide an LLM to absolute correctness, Loop Engineering designs autonomous, multi-agent feedback systems structured around closed-loop cycles: Discover, Plan, Execute, Verify, and Iterate.
When you build systems this way, you treat the underlying LLM simply as an execution engine the real intelligence lives in the orchestration layer—the state machine, the memory routers, and the deterministic feedback paths that decide whether an output is fit for production or requires re-evaluation.
Why Custom State over Native CrewAI Flows?
While CrewAI provides built-in Flows with a Pydantic-based state machine, it is insufficient for production-grade self-improving agents.
| Aspect | Native CrewAI Flows | Our Custom Stateful System (TWV) |
|---|---|---|
| Persistence | Volatile in-memory. State is lost on application crash or restart. | Physical store (SQLite). Full audit trail and crash recovery. |
| Crash Recovery | Cannot resume a failed or interrupted run. | Pause and Resume. Can reload any past session and resume execution from the last step. |
| Escalation Logic | Linear listener methods (@router, @listen) that clutter the orchestrator. | Decoupled Controller. Autonomous decision engine (FeedbackController) with dynamic retry/reassign/replan rules. |
| Memory Isolation | Global state structure shared directly across all agents. | Hierarchical Scopes (/twv/session/*, /twv/workers/*) to prevent prompt context clutter. |
How the Thinker-Worker-Verifier pattern structures stateful execution
The Thinker-Worker-Verifier pattern is a highly structured implementation of Loop Engineering: It splits cognitive responsibilities across three specialized roles, preventing a single agent from suffering from cognitive overload or grading its own work.
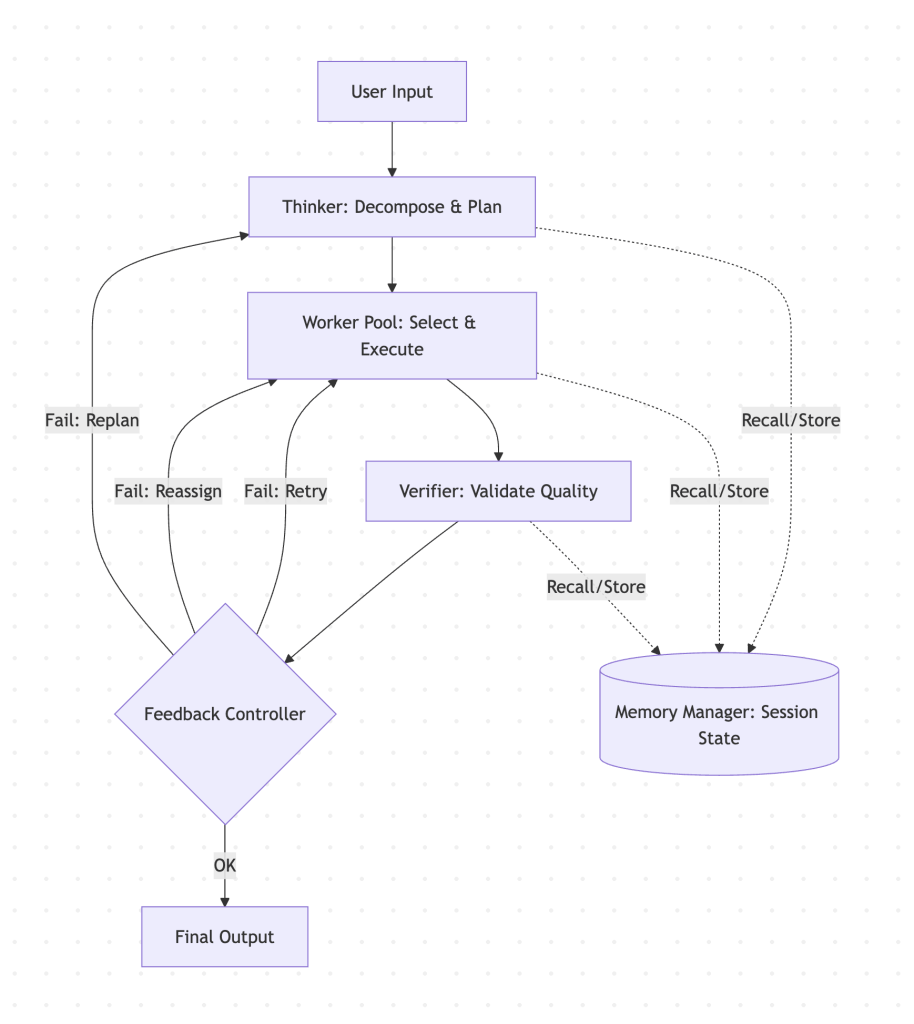
The Thinker (Planner & Router)
The Thinker sits at the top of the hierarchy and It does not write the final response or compile the target code: its sole responsibility is to analyze the user input, pull historical context from the memory layer, and output a structured plan—often a PlanPacket validated via Pydantic. It looks at the available catalog of workers and selects the most qualified specialist.
Importantly, the Thinker can trigger a “self-call” (or recursive planning) if it detects that a problem is too vague or requires further breakdown before execution can begin.
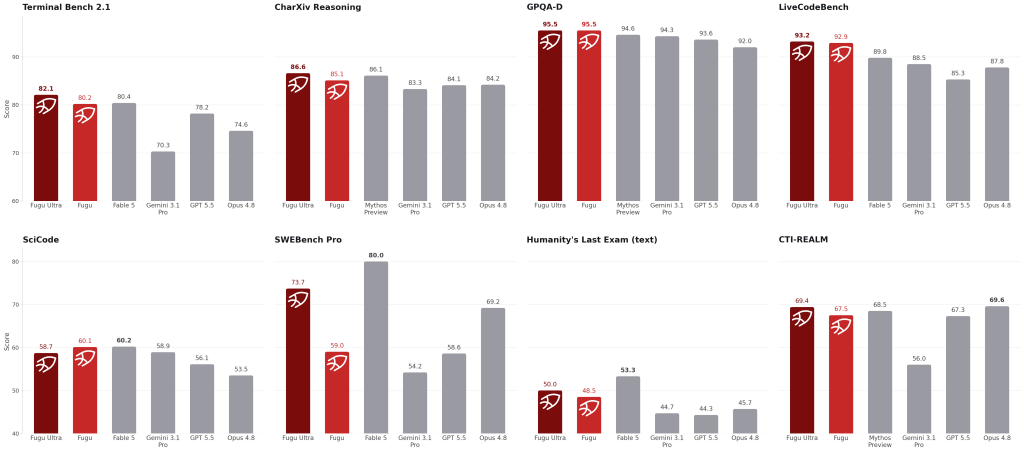
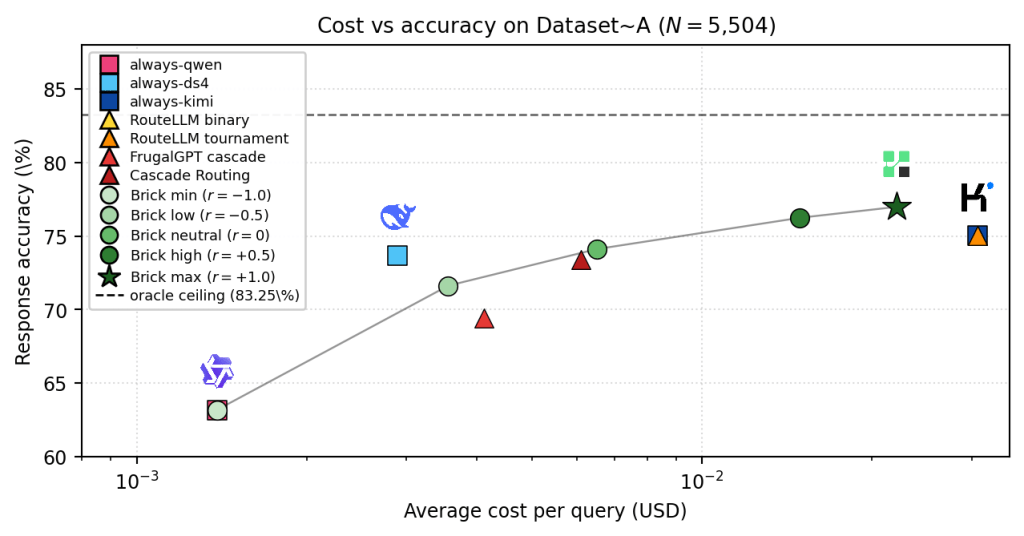
We develop Brick (Brick: Spatial Capability Routing for the Mixture-of-Models (MoM) Paradigm): it’s a semantic routing that drive prompt to the right model making your pipeline more efficient in terms of time and costs (up to 80% cost reduction).
The model is available on Regolo and you can testi it free for 30 days, or you can download your favourite version (quantized, fp8, etc.) going to the regolo Hugging Face profile page.
The Worker (Specialized Executor)
The Worker is an execution agent, isolated from the high-level planning worries: It receives a targeted sub-task, the plan constraints, and any prior feedback from the Verifier. Because its scope is tightly constrained, the Worker can leverage specialized tools—such as secure sandboxed runtimes, search APIs, or database connections—without risking context drift.
In a robust worker pool, you might have different profiles: a writer worker for documentation, a coder worker for generating TypeScript or Python, and an analyst worker for evaluating raw logs.
The Verifier (Impartial Critic)
The Verifier is the quality control gate, allowing a Worker to verify its own output is a recipe for silent failures and hallucinated success.
The Verifier evaluates the Worker’s output strictly against the success criteria defined in the initial plan. It outputs a structured VerificationReport containing a boolean status and a concrete recommendation for the next action.
Under the hood of the state machine
A common failure mode in multi-agent designs is “infinite looping” or decision oscillations. Left to their own devices, LLM-based critics will often recommend retrying the same failed action indefinitely, burning API tokens and driving latency through the roof.
To prevent this, the Thinker-Worker-Verifier pattern separates the execution layer (the LLM agents) from the control layer (a deterministic, zero-LLM state machine).
Consider how we structure this in code. We can define a deterministic FeedbackController that parses the Verifier’s recommendation but applies strict corporate safety guardrails:
| Attempted Action | Condition | Escalation Path | Purpose |
|---|---|---|---|
| RETRY | retry_count < max_retries | Proceed with same Worker | Standard local optimization of the output. |
| RETRY | retry_count >= max_retries | Escalate to REASSIGN | Abandon the current Worker; try another specialist. |
| REASSIGN | reassign_count < max_reassigns | Select different Worker | Taps a different specialized agent from the pool. |
| REASSIGN | reassign_count >= max_reassigns | Escalate to REPLAN | The current plan is fundamentally flawed; rebuild it. |
| REPLAN | replan_count < max_replans | Thinker rebuilds plan | Restructures the strategy based on verification feedback. |
| REPLAN | replan_count >= max_replans | Forced RETRY (Final) | Last-gasp effort to polish the best available output. |
By using this structured framework, the system is mathematically guaranteed to terminate. We avoid the trap of hoping the LLM will decide when to stop. Instead, the runtime code enforces these boundaries.
Bridging the gap: Our lightweight loop vs Sakana AI’s Fugu
While our Thinker-Worker-Verifier codebase offers a reliable, production-ready framework for everyday business tasks, it is essential to understand how it contrasts with the highly complex, academic mechanics of Sakana AI’s Fugu.
Our project is a deterministic, human-designed representation of stateful multi-agent looping – Fugu, on the other hand, is an evolutionary search system that discovers optimal loops autonomously.
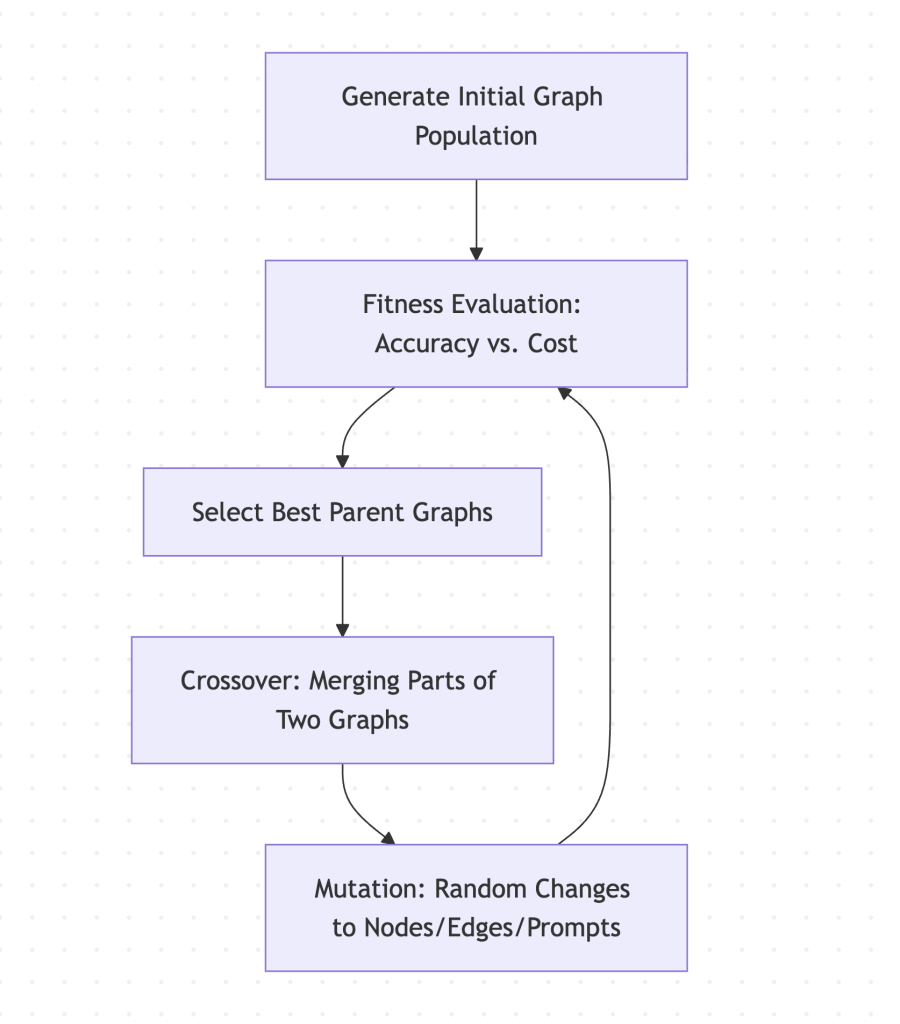
The key differences highlight why both approaches have distinct places in the AI engineering landscape:
- Topology Generation: our loop is structurally static, the progression from Thinker to Worker, and finally to Verifier, is hardcoded in Python. Fugu begins with a pool of basic nodes and uses genetic algorithms (mutations and crossovers) to dynamically assemble, prune, and test custom graph structures, discovering unconventional agent connections that a human developer would never think to write.
- Evaluation Framework (Fitness vs. Runtime Verification): in our lightweight system, quality is validated at runtime for a single request using our
Verifieragent and standard Pydantic assertions. Fugu relies on an offline evolutionary training phase: It runs thousands of candidate graphs against a structured validation dataset (or benchmark), evaluating each graph’s aggregate performance and API token cost (the fitness function) before choosing the winning workflow to deploy. - Orchestration Overhead: to remain highly accessible, our project utilizes CrewAI, which wraps agents and tasks in clean, high-level abstractions. Fugu is designed for massive scale, utilizing lightweight, custom-built, parallelized execution frameworks to run hundreds of mutant graphs simultaneously without suffering from framework-level latency.
Ultimately, we believe that you do not always need to run a computationally expensive evolutionary search to reap the benefits of stateful loops.
Our Thinker-Worker-Verifier setup serves as an immediate, pragmatic implementation of the very patterns Fugu’s research proved to be optimal. It packages the power of a self-correcting feedback loop into a clean, human-readable codebase that you can deploy to production today.
Despite these massive differences, there is a distinct advantage to our simplified TWV approach: you do not always need to burn thousands of dollars in GPU computing to run evolutionary algorithms just to find a workflow for your business application.
By hardcoding the Thinker-Worker-Verifier loop, we have taken what academic research has proven to be the most optimal evolved layout—one featuring strict planning, specialized execution, independent critique, and deterministic routing—and packaged it into an accessible, readable codebase.
It is a highly reliable “derivative” designed for enterprise systems where predictability and GDPR-compliant data sovereignty are more important than searching for theoretical, marginal performance gains.
Github Codes
You can download the codes on our Github repo, just download and follow the README steps. If need help you can always reach out our team on Discord 🤙
FAQ
How does the Thinker-Worker-Verifier pattern prevent infinite loops?
We prevent infinite looping by using a deterministic, code-based FeedbackController that sits outside the LLM execution layer. This controller tracks metrics like retry_count, reassign_count, and replan_count, automatically forcing termination or escalation to a different path once safety limits are hit, rather than relying on an LLM to decide when to stop.
Can we use different LLM backends for each agent in the loop?
Yes, and we highly recommend doing so to optimize cost and performance. You can deploy a highly capable, reasoning-heavy model for the Thinker and Verifier roles, while using smaller, faster, and cheaper fine-tuned models for the specialized Worker roles, tailoring your compute budget to the complexity of each task.
How does this pattern differ from traditional Prompt Engineering?
Traditional Prompt Engineering relies on crafting a single, static prompt to guide an LLM to a complex goal in one shot. The Thinker-Worker-Verifier pattern represents Loop Engineering, which builds a dynamic, multi-agent system with planning, execution, autonomous verification, and error-handling paths to iteratively refine the output until it meets defined quality gates.
What is the role of the memory layer in this architecture?
The memory layer prevents cumulative context pollution by isolating state into hierarchical scopes. Instead of feeding the entire, messy history of every failed attempt back to the agents, the memory manager selectively recalls and formats only the specific context (like the current plan, the specific worker history, or the latest validation report) required for the active node.
Start your free 30-day trial at regolo.ai and deploy LLMs with complete privacy by design.
👉 Talk with our Engineers or Start your 30 days free →
- Discord – Share your thoughts
- GitHub Repo – Code of blog articles ready to start
- Follow Us on X @regolo_ai
- Open discussion on our Subreddit Community
- Full list of model available: Models
Built with ❤️ by the Regolo team. Questions? regolo.ai/contact or chat with us on Discord