
How to Get Started
Step 1
Sign Up and get your Api Key and use with UNLIMITED tokens for 30 days.
Step 2
Paste the URL from Huggingface repository. (Ex: https://huggingface.co/nvidia/NVIDIA-Nemotron-3-Super-120B-A12B-NVFP4)
Step 3
Choose the GPU machine to deploy.
That’s all! You’re ready to use the model in few minutes without infrastructure complexity in few minutes.
Document Parsing & Information Extraction
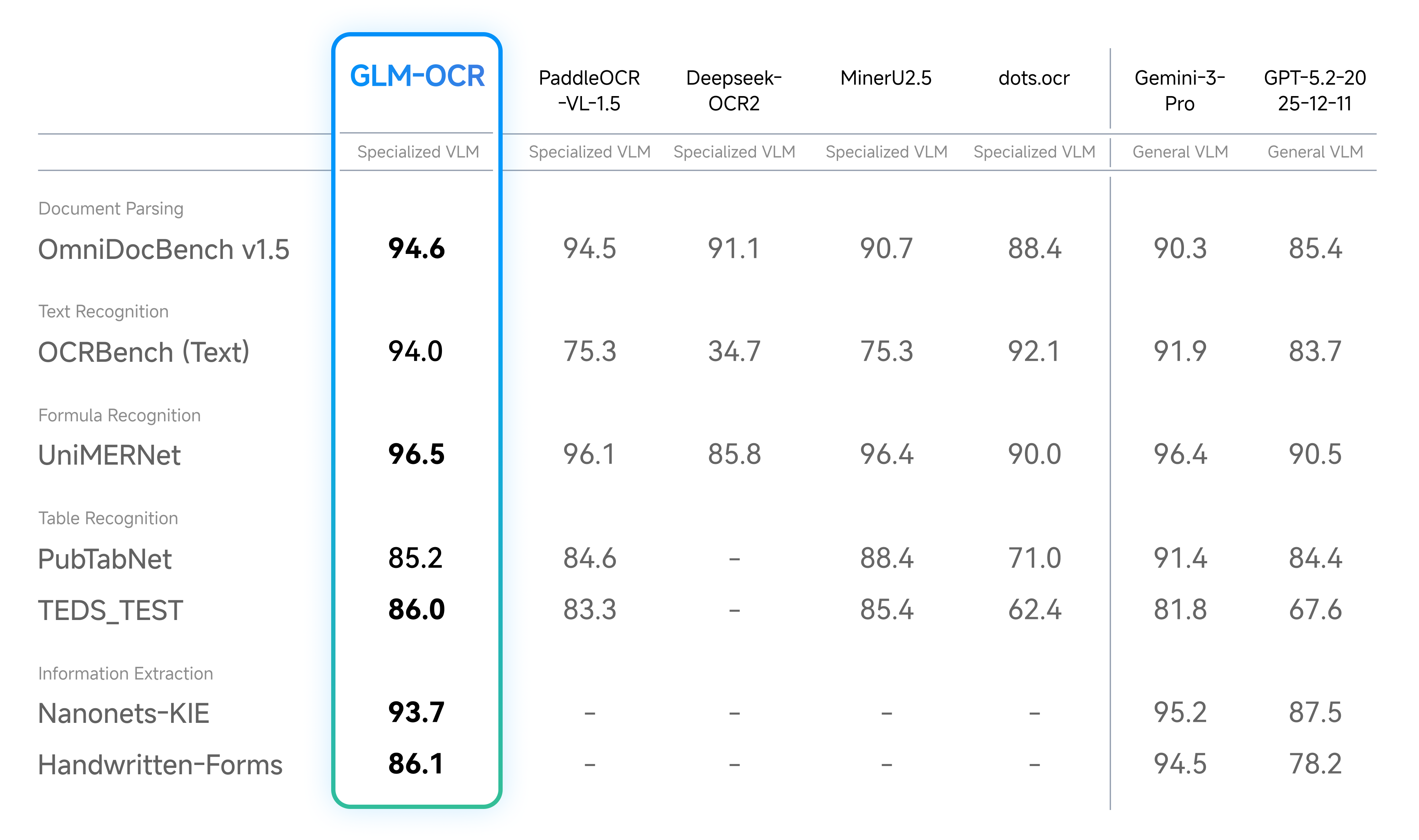
Real-World Scenarios Performance
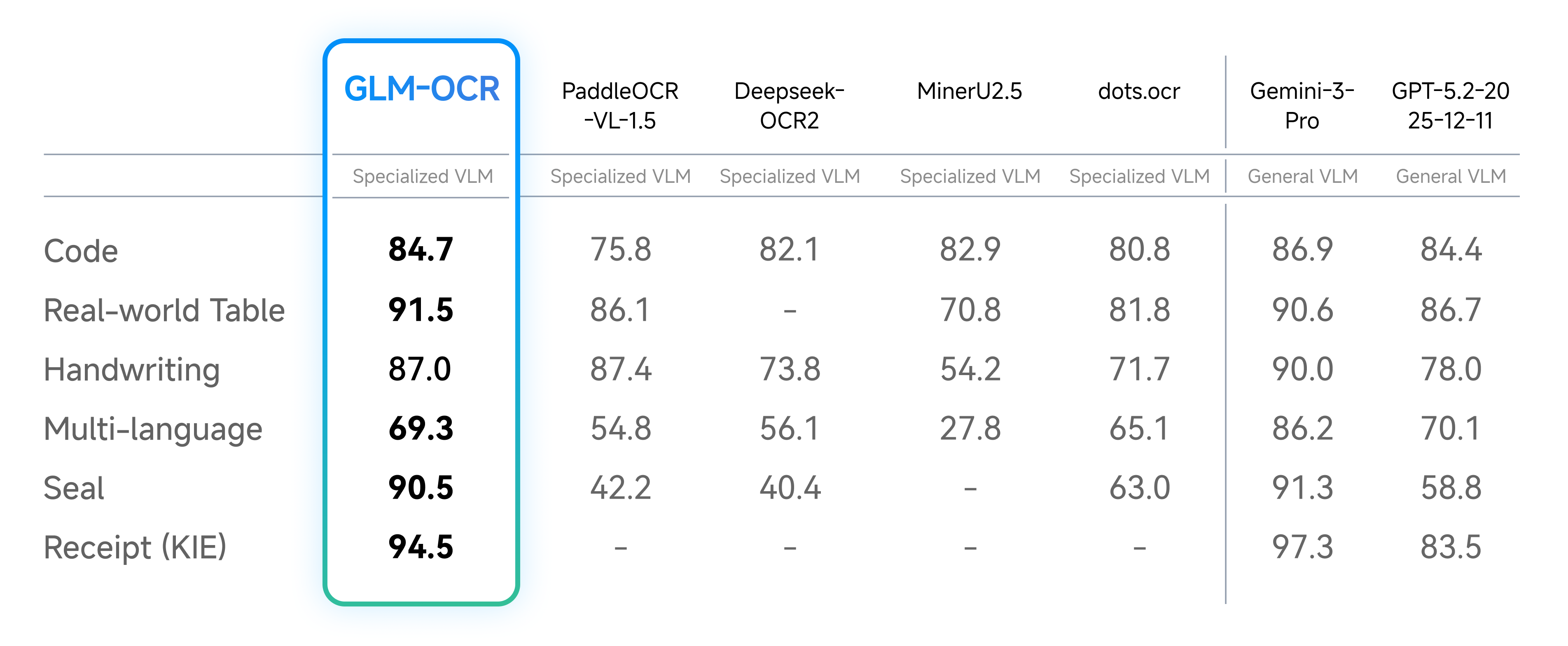
Speed Test
Applications & Use Cases
- High‑accuracy OCR for PDFs, scanned documents, contracts, and receipts, including mixed text, stamps, seals, and complex layouts.
- Table and form extraction that recovers structured data from financial statements, invoices, reports, and spreadsheets with SOTA OmniDocBench performance.
- Formula and code recognition in scientific papers, textbooks, and developer documentation, turning screenshots and PDFs into editable LaTeX or source code.
- Private, on‑device document parsing on laptops, workstations, or edge boxes thanks to the 0.9B size and <1.5 GB VRAM requirement (≈1 GB when quantized).
- Pre‑processing stage in RAG pipelines, where GLM‑OCR converts large batches of PDFs and images into clean, layout‑aware text chunks for downstream LLMs.
- Automation in back‑office workflows (KYC, compliance, backlogs) where robust OCR across stamps, signatures, and noisy scans is critical for reliability.