
How to Get Started
Step 1
Sign Up and get your Api Key and use with UNLIMITED tokens for 30 days.
Step 2
Paste the URL from Huggingface repository: https://huggingface.co/nvidia/Nemotron-Cascade-2-30B-A3B
Step 3
Choose the GPU machine to deploy.
That’s all! You’re ready to use the model in few minutes without infrastructure complexity in few minutes.
Additional Info
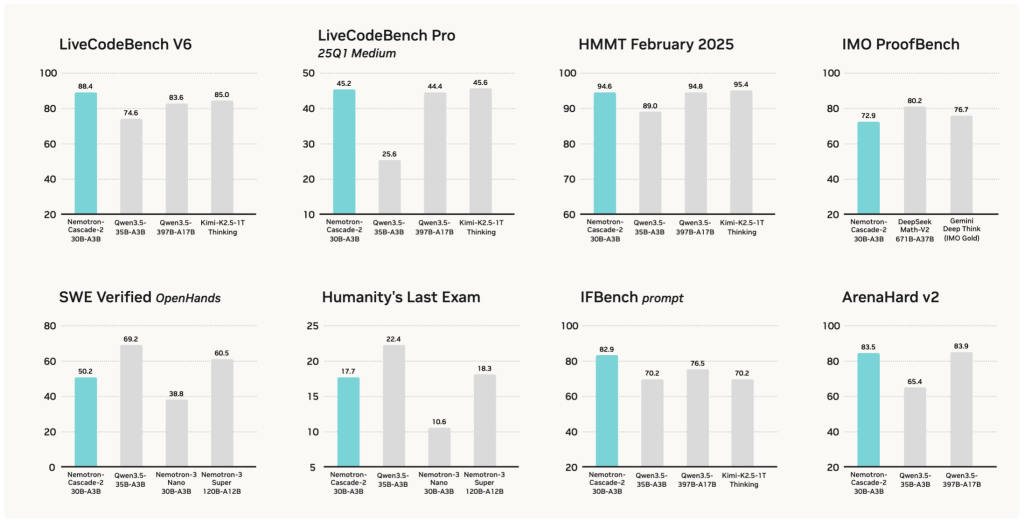
Applications & Use Cases
- Math and competition‑grade solvers for Olympiad‑style problems (IMO, AIME, HMMT, ICPC), where the model already achieves gold‑medal level results.
- Agentic coding assistants and SWE copilots that use the thinking mode plus tools (for example OpenHands) to solve non‑trivial programming and algorithmic tasks.
- Long‑context RAG and technical Q&A pipelines over textbooks, proofs, research papers, and codebases using the 262k+ token window for cross‑document reasoning.
- Governance and evaluation agents that verify or critique other models’ reasoning by comparing chains of thought and final answers at competition difficulty.
- Cost‑efficient “near‑frontier” deployments where a single RTX‑class GPU (around 24 GB with quantization) must deliver 120B‑tier reasoning quality using only 3B active parameters