Zyphra made ZAYA1-8B strong not by making it huge, but by making it efficient at every layer of the stack. The short version is simple: they built a small MoE that activates only about 0.76B parameters at a time, trained it for reasoning from the start, reinforced it with a staged RL pipeline, and then gave it a smarter way to “think longer” at inference time with Markovian RSA.
What ZAYA1-8B is
ZAYA1-8B is a reasoning-focused mixture-of-experts model with 8.4B total parameters, but only about 0.76B active parameters per token. That matters because it lets the model behave more like a much larger system without paying the full inference cost of a dense model every time.
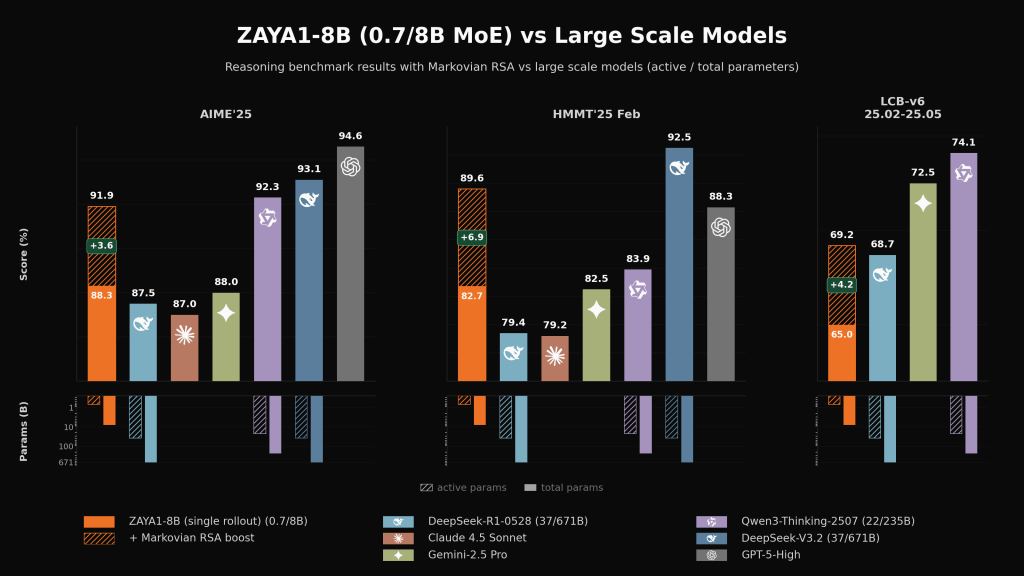
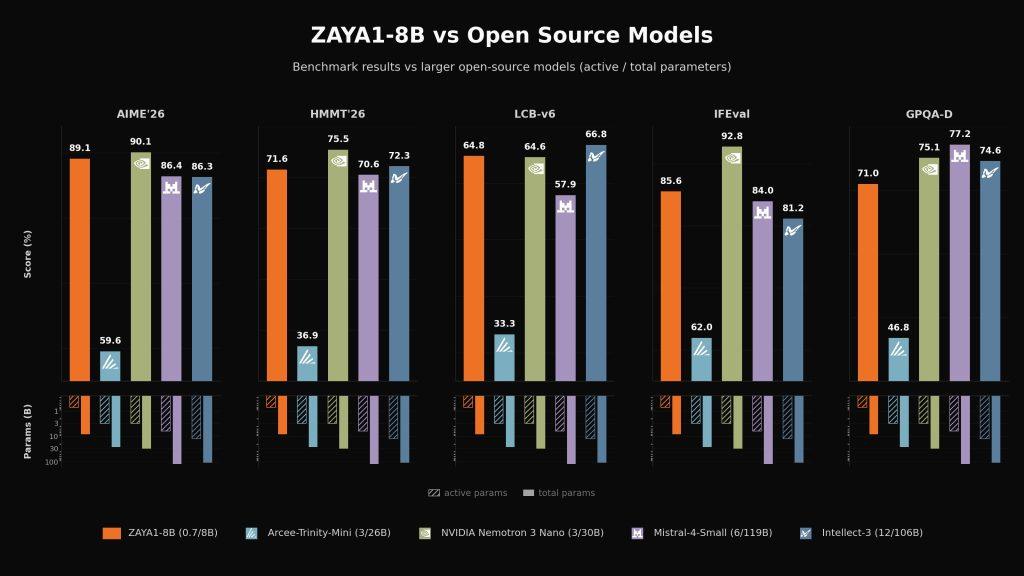
Zyphra says ZAYA1-8B matches or exceeds some much larger open-weight reasoning models on several math and coding benchmarks, and stays competitive with larger frontier systems on hard reasoning tasks.
With Markovian RSA, the company reports 91.9% on AIME’25 and 89.6% on HMMT’25.
What they changed in the model
The first big upgrade is something Zyphra calls Compressed Convolutional Attention, or CCA. Instead of handling attention in the usual heavy way, CCA mixes sequence information in a compressed latent space, which cuts prefill compute and reduces KV-cache size by 8x relative to full multi-head attention.
They found a cheaper way for the model to remember and connect pieces of text over long contexts. That made long-context midtraining and RL more practical at their compute budget.
The second upgrade is the ZAYA1 router: the model gets better at choosing the right expert for the job. Zyphra argues this better routing reduces balancing instability, improves expert specialization, and makes top-1 routing work well enough that a residual expert is unnecessary.
The third upgrade is learned residual scaling. Zyphra uses it to control how much signal from earlier layers is kept or damped as the model gets deeper, and the report says it helps control residual-norm growth at negligible parameter and FLOP cost.
What they changed in training
One of the smartest tricks here is answer-preserving trimming. When a reasoning trace was too long for the current context window, Zyphra cut the tail of the reasoning while keeping the final answer, instead of dropping the sample or cutting off the answer entirely.
That matters because it preserves the part of the reasoning trace where the model often plans and breaks the problem down. In simple terms, they taught the model to see real reasoning examples early, even when those examples were too long to fit in full.
The long-context schedule also mattered. Zyphra trained through 4K pretraining, then 32K midtraining, then 131K SFT, while keeping reasoning-heavy data as a major part of the mix in the later stages.
After SFT, Zyphra used a staged RL pipeline rather than one generic post-training pass. The pipeline moved through reasoning warmup, a 400-task RLVE-Gym curriculum, math and code RL with test-time-compute traces, and then a lighter behavioral RL phase for chat, instruction following, and writing style.
This is a big part of why the model improved. Zyphra first pushed the system on tasks with verifiable answers, like math, puzzles, and code, and only later tuned softer behaviors like chat quality.
Why Markovian RSA is the real multiplier
instead of asking the model for one long thought, Zyphra asks for several attempts, keeps the useful ending from each one, and uses those fragments to build a better next attempt. This lets the model “think longer” without dragging its full reasoning history forever.
Zyphra says the method keeps context length bounded by carrying forward only a 4K-token tail, even while using much larger total reasoning budgets across rounds.
They co-designed the architecture, the data, the RL pipeline, and the inference harness so that all four parts support the same job, which is efficient reasoning.
Why this matters for real deployment
ZAYA1-8B is also notable because Zyphra says pretraining, midtraining, and supervised fine-tuning were done on a full AMD stack, using 1,024 MI300X nodes with AMD Pensando Pollara interconnect in a cluster built with IBM. That makes the release relevant beyond model quality, because it shows a serious reasoning model can be developed outside the default NVIDIA-only story.
For teams building in Europe, this is the part worth watching. A model that is smaller in active compute, open under Apache 2.0, and designed for efficient long-context reasoning is easier to connect to local infrastructure, privacy constraints, and cost-aware deployment choices than a giant closed frontier model.
The broader lesson is not that every company should copy Zyphra’s exact recipe. It is that small models can improve a lot when architecture, training data, post-training, and inference-time compute are designed as one system instead of four separate optimizations.
FAQ
What is ZAYA1-8B in one line?
It is an 8.4B-total MoE reasoning model that activates only about 0.76B parameters per token and still performs competitively on hard math, coding, and reasoning benchmarks.
What did Zyphra do differently?
The main changes were CCA attention, a stronger MLP-based router, residual scaling, reasoning-first pretraining with answer-preserving trimming, a multi-stage RL pipeline, and Markovian RSA at inference time.
Why is Markovian RSA important?
Because it lets the model use more test-time reasoning without letting context length grow without bound, and Zyphra reports large gains from it on hard math tasks.
Was this trained on AMD?
Yes. Zyphra says core pretraining, midtraining, and SFT were run on an AMD MI300X stack with Pollara networking.
Is the model open?
Yes. Zyphra says ZAYA1-8B is released under Apache 2.0
Start your free 30-day trial at regolo.ai and deploy LLMs with complete privacy by design.
👉 Talk with our Engineers or Start your 30 days free →
- Discord – Share your thoughts
- GitHub Repo – Code of blog articles ready to start
- Follow Us on X @regolo_ai
- Open discussion on our Subreddit Community
Built with ❤️ by the Regolo team. Questions? regolo.ai/contact or chat with us on Discord