
Single-agent LLMs hallucinate, miss context, or produce shallow analysis. Multi-agent systems fix this by giving specialized roles, opposing incentives (especially a dedicated critic), and layered reviews — exactly what the arXiv paper 2601.14351 demonstrated with >90 % internal error interception in real financial tasks.
In this tutorial you’ll build a production-ready competitor intelligence crew that takes any product/company and outputs a professional, fact-checked strategic report. Perfect for product managers, strategy teams, and developers who need trustworthy AI output.
What You’ll Build
Input: “Cursor AI code editor” + competitors Output: A polished Markdown competitive intelligence report (executive summary, SWOT tables, pricing comparison, risks, recommendations, sources).
Why This Architecture Works
- Specialized roles → deeper expertise per agent
- Skeptical Critic (the “rival”) → catches hallucinations and biases
- Hierarchical orchestration → manager coordinates like a real team lead
- Optional Flows → automatic retry loops until quality threshold is met
Step 1: Setup (5 minutes)
# Recommended: use uv
uv pip install crewai crewai[tools]
# Or classic
pip install crewai crewai-toolsCode language: PHP (php)Create a .env file:
OPENAI_API_KEY=sk-...
SERPER_API_KEY=... # free tier at serper.devCode language: PHP (php)Step 2: Complete Runnable Code (main.py)
import os
from dotenv import load_dotenv
from crewai import Agent, Task, Crew, Process
from crewai_tools import SerperDevTool, ScrapeWebsiteTool
from langchain_openai import ChatOpenAI
load_dotenv()
# Tools
search_tool = SerperDevTool()
scrape_tool = ScrapeWebsiteTool()
# LLMs (you can mix models for diversity & cost)
research_llm = ChatOpenAI(model="gpt-4o-mini", temperature=0.3)
critic_llm = ChatOpenAI(model="gpt-4o", temperature=0.1) # stronger reasoning
writer_llm = ChatOpenAI(model="gpt-4o-mini", temperature=0.7)
# ====================== AGENTS ======================
researcher = Agent(
role="Senior Market Researcher",
goal="Gather comprehensive, up-to-date, evidence-backed information on competitors",
backstory="You are an extremely thorough researcher who always verifies sources "
"and digs into product pages, news, reviews, pricing, and recent launches.",
tools=[search_tool, scrape_tool],
llm=research_llm,
verbose=True,
allow_delegation=False,
)
analyst = Agent(
role="Strategic Competitive Analyst",
goal="Turn raw research into deep strategic insights, differentiators, and risks",
backstory="You think like a top-tier management consultant (McKinsey/Bain level). "
"You excel at identifying patterns, opportunities, and threats.",
llm=research_llm,
verbose=True,
allow_delegation=False,
)
critic = Agent(
role="Skeptical Quality Critic",
goal="Find every factual error, hallucination, bias, logical gap, or missing perspective",
backstory="You are a ruthless but constructive auditor. Your only job is to "
"protect the team from bad decisions based on flawed analysis.",
llm=critic_llm,
verbose=True,
allow_delegation=False,
)
writer = Agent(
role="Executive Report Writer",
goal="Produce clear, professional, visually structured competitive intelligence reports",
backstory="You write for C-level executives. Your reports are concise, "
"action-oriented, and use excellent Markdown formatting and tables.",
llm=writer_llm,
verbose=True,
allow_delegation=False,
)
# ====================== TASKS ======================
research_task = Task(
description="Research {product} and its main competitors ({competitors}). "
"Cover features, pricing, recent news, customer sentiment, and market positioning.",
expected_output="Detailed research summary in Markdown with sources and quotes.",
agent=researcher,
)
analysis_task = Task(
description="Perform deep competitive analysis: SWOT, differentiation, risks, "
"and strategic recommendations based on the research.",
expected_output="Structured strategic analysis with tables and clear insights.",
agent=analyst,
context=[research_task],
)
critique_task = Task(
description="""Critically review the entire analysis. Flag any:
- Factual inaccuracies or outdated information
- Logical inconsistencies or biases
- Missing important angles
If everything is solid, reply exactly 'CRITIQUE PASSED'.
Otherwise reply 'REVISIONS NEEDED:' followed by detailed fix list.""",
expected_output="Critique result + revision instructions if needed",
agent=critic,
context=[research_task, analysis_task],
)
report_task = Task(
description="Write the final executive competitor intelligence report. "
"Incorporate all previous work and any critic revisions. "
"Include executive summary, tables, and actionable recommendations.",
expected_output="Complete professional Markdown report ready for executives.",
agent=writer,
context=[research_task, analysis_task, critique_task],
output_file="output/competitor_report.md",
)
# ====================== CREW ======================
crew = Crew(
agents=[researcher, analyst, critic, writer],
tasks=[research_task, analysis_task, critique_task, report_task],
process=Process.hierarchical, # manager coordinates
manager_llm=ChatOpenAI(model="gpt-4o", temperature=0.1),
verbose=2,
memory=True, # unified memory system
cache=True,
)
# ====================== RUN ======================
if __name__ == "__main__":
result = crew.kickoff(inputs={
"product": "Cursor AI code editor",
"competitors": "GitHub Copilot, Windsurf, Replit Agent"
})
print("\n✅ Report generated!")
print("📁 Saved to: output/competitor_report.md")Code language: Python (python)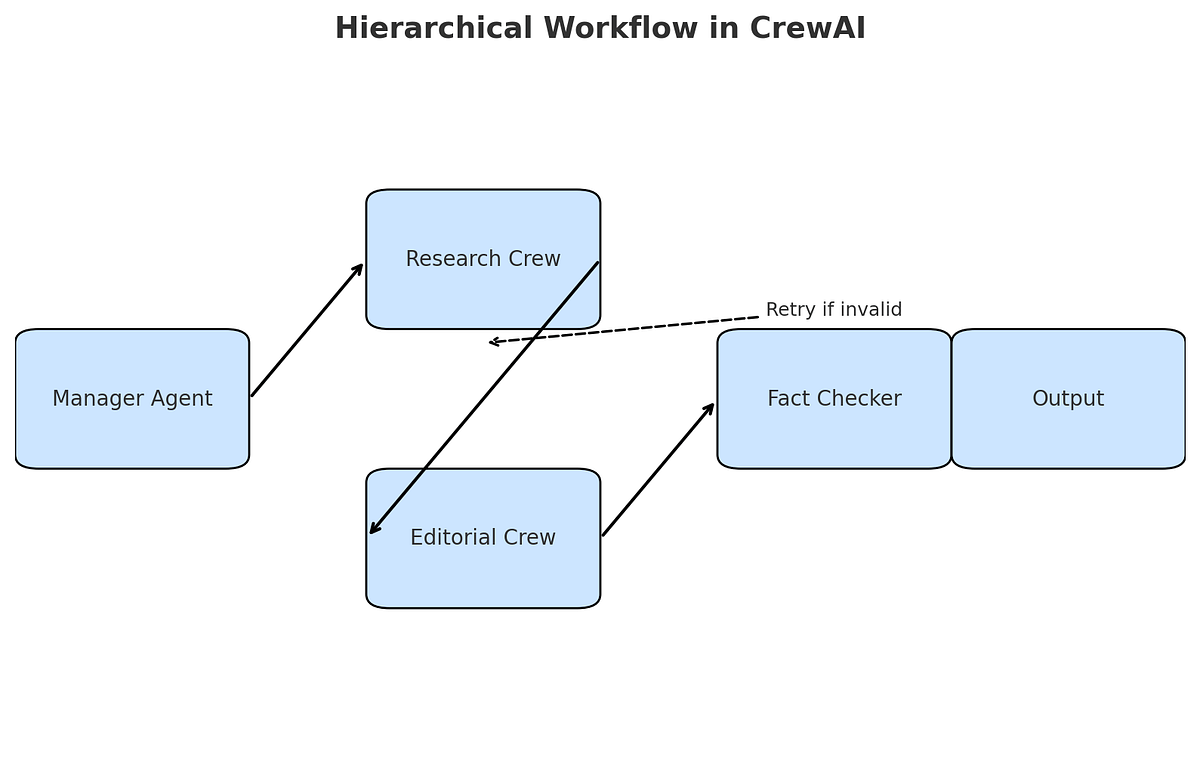
Mastering CrewAI Flows: Building Hierarchical Multi-Agent Systems | by Jishnu Ghosh | Medium
Step 3: Run It
mkdir output
python main.pyCode language: CSS (css)You’ll get a high-quality report with far fewer hallucinations thanks to the dedicated critic.
Going Further: Automatic Retry Loop with CrewAI Flows
For true “Team of Rivals” reliability, wrap the crew in a Flow that automatically loops back to the analyst if the critic rejects the output (max 3 attempts).
See the official self_evaluation_loop_flow example in the CrewAI repo for the pattern — it’s only ~30 extra lines and gives production-grade self-correction.
Resources
- CrewAI docs: https://docs.crewai.com
- Official examples repo (including stock_analysis and self_evaluation_loop_flow): https://github.com/crewAIInc/crewAI-examples
- Original paper that inspired this: https://arxiv.org/abs/2601.14351
🚀 Ready? Start your free trial on today
- Discord – Share your thoughts
- GitHub Repo – Code of blog articles ready to start
- Follow Us on X @regolo_ai
- Open discussion on our Subreddit Community
Built with ❤️ by the Regolo team. Questions? regolo.ai/contact or chat with us on Discord