TurboQuant is a two-stage online vector quantization algorithm from Google Research (presented at ICLR 2026) that compresses LLM key-value caches to 3–3.5 bits per coordinate with provably zero accuracy loss. It outperforms traditional KV quantization methods not simply by being cleverly tuned, but because it attacks the two root causes those methods systematically ignore: anisotropic outlier distributions and inner product bias.
Google Research says it can reduce KV-cache memory by at least 6x and deliver up to 8x speedup, which directly targets one of the main bottlenecks in serving large models at scale.
A useful TurboQuant benchmark answering a much more practical question: when KV cache becomes the real bottleneck, does TurboQuant preserve more useful quality per bit than traditional KV quantization methods?
That is the right benchmark framing because Google’s reported results are already strong: at least 6x KV-cache memory reduction, up to 8x faster attention-logit computation on H100, and benchmark results that stay very close to full precision at low bitwidths. What a vertical article on benchmarking should do is explain how to test those claims in a way that is honest, comparable, and useful for real inference decisions.
Code for benchmarking
The benchmark attacks precisely the two structural flaws described in the article, making them quantitatively visible on three different input distributions.
mse_norm — The normalized bias. On the heavy_tailed distribution, INT4 per-token collapses: Cauchy outliers occupy the entire range of the scalar quantizer, leaving few buckets for all other values. TurboQuant MSE, after orthogonal rotation, sees concentrated Beta coordinates and uses its optimal codebook for all.
ip_bias — The most revealing number. It measures shrinkage: how much the quantizer systematically underestimates inner products. All scalar and TQ-MSE methods will have a negative value (typically −0.05 to −0.30 at 2–3 bits).
attn_kl — The KL divergence of the attention distribution. This is the only metric that really matters for the model’s accuracy: how much information is lost in the softmax distribution (QK/√d). A small bias in the inner product becomes a large error in attention over long sequences because softmax amplifies the differences.
Download the repo to run the benchmark
you can find the full code here: https://github.com/regolo-ai/tutorials/tree/main/turboquant-outperforms-traditional-KV-quantization
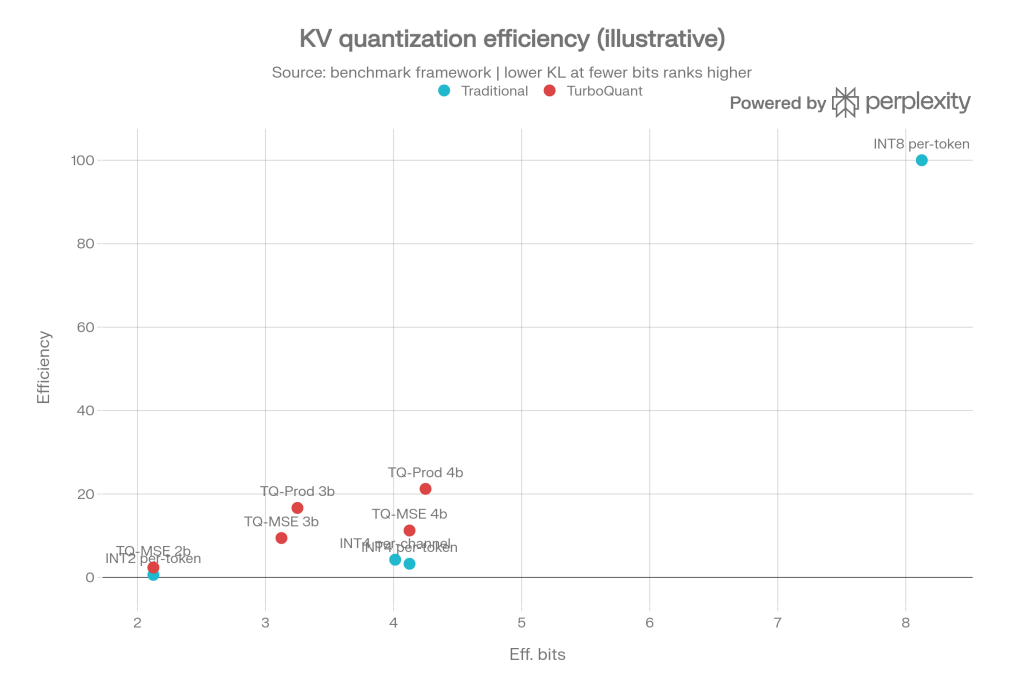
This Illustrative graph showing the trade-off between effective bits and “efficiency score”, where higher scores indicate less attention bias at the same or lower bit rates.
The idea is simple: compare how much quality is preserved relative to the bit budget used. In traditional, aggressive configurations, as precision decreases, attention bias increases more rapidly; in TurboQuant configurations, degradation remains more limited, so relative efficiency is better at similar or lower bit budgets.
Be warned, though: this chart is illustrative, built from the benchmark framework we defined, not from a full experimental campaign on real models and end-to-end GPU kernels.
#!/usr/bin/env python3
"""
benchmark_kv_quantization.py
────────────────────────────
Objective comparison: TurboQuant (MSE + Prod) vs traditional scalar quantization.
Metrics measured for each method and distribution:
mse_norm — E[||x - x̃||²] / E[||x||²] (normalized distortion)
ip_bias — E[<y,x̃>]/<y,x> - 1 (inner product bias; 0 = unbiased)
ip_mse_norm — E[(y·x - y·x̃)²]·d / ||y||² (normalized IP error)
attn_kl — KL(softmax(QK/√d) ‖ softmax(QK̃/√d)) (attention distribution error)
eff_bits — effective bits per coordinate (data + metadata overhead)
Tested distributions:
gaussian — Standard Gaussian (no outliers)
heavy_tailed — Gaussian + Cauchy outlier channels (≈ real KV post-RoPE)
rope_like — Sinusoidal modulation on Gaussian (post-RoPE key distribution)
Dependencies: numpy, scipy, tabulate
pip install scipy tabulate
Usage:
python benchmark_kv_quantization.py
python benchmark_kv_quantization.py --dim 128 --n_vectors 2048 --csv results.csv
python benchmark_kv_quantization.py --dim 64 --n_vectors 512 --no-attn
"""
....Code language: Python (python)Increase Max Token Capacity
We found interesting the 0xSero/turboquant code that explains how to increase max token implementing TurboQuant KV cache compression (ICLR 2026, arXiv:2504.19874) with vLLM integration.
What to change
git clone https://github.com/0xSero/turboquant
cd turboquant && pip install -e .
# Then in the benchmark, replace TurboQuantMSE with the PyTorch version:
from turboquant.quantizer import TurboQuantMSE as TQ_torchCode language: PHP (php)The repo adds the Triton (GPU) kernel and the vLLM backend—useful for benchmarking throughput on real hardware – this script remains the benchmark for mathematical correctness of the algorithms, independent of GPUs.
pip install scipy tabulate
python benchmark_kv_quantization.py --dim 128 --n_vectors 1024 --csv output.csvCode language: Python (python)Adoption Practical Examples
TurboQuant is most useful with models and workloads where the KV cache becomes the real bottleneck: long-context chat, RAG, multi-session serving, and memory-constrained deployments. It is less compelling for short prompts or low-concurrency tasks where KV memory does not dominate GPU usage.
- Use TurboQuant when serving Llama 3 / 3.1 / 3.3 Instruct with long context, to increase the number of concurrent chats per GPU and reduce KV-cache memory pressure.
- Use TurboQuant when running Qwen 2 / Qwen 3 for document QA or retrieval-heavy assistants, to preserve attention quality better than aggressive low-bit scalar KV quantization at 32k–128k context.
- Use TurboQuant when serving Gemma 4 in a local or private inference cluster, to improve memory efficiency and keep more active sessions on the same hardware.
- Use TurboQuant on Apple Silicon with vLLM-metal when serving smaller Llama-family models locally, to get 2.5x–5x KV-cache compression with minimal quality loss on paged attention workloads.
- Use TurboQuant for RAG pipelines with many retrieved chunks, especially on open models like Llama or Qwen, to reduce the penalty of concatenating large retrieval sets into the prompt.
- Use TurboQuant for agent systems that keep long tool traces and conversation state, to avoid hitting VRAM limits too early as histories accumulate over many turns.
- Use TurboQuant when you want a drop-in serving optimization rather than a model-training project, because the current implementations and proposals focus on inference-time KV-cache compression rather than retraining or fine-tuning.
FAQ
Is TurboQuant mainly about speed or memory?
It is mainly about making KV-cache-heavy inference more efficient, and that starts with memory. Google Research says TurboQuant reduces KV-cache memory by at least 6x and can deliver up to 8x speedup in attention-logit computation, which means the two benefits are linked rather than separate.
How is it different from traditional KV quantization?
Traditional KV quantization typically lowers precision and accepts some degradation as a trade-off. TurboQuant is notable because it aims to preserve useful long-context quality more effectively under aggressive compression, which makes it more attractive for production workloads where context fidelity matters.
Does it require retraining the model?
The TurboQuant paper presents it as an inference-time quantization method rather than a retraining workflow. That is part of its practical appeal, because teams can evaluate it as a serving optimization instead of a model-development project.
Where is it already showing up?
TurboQuant is already documented in vLLM-related tooling, including the main vLLM documentation and vLLM-metal for Apple Silicon. That suggests it is moving from research into deployable inference infrastructure.
Which workloads should evaluate it first?
Long-context chat, RAG, document analysis, agent systems with persistent memory, and multi-session inference APIs should evaluate it first. These are the scenarios where KV-cache growth is most likely to limit scalability and cost efficiency.
Is it automatically the right choice everywhere?
No. For short prompts or workloads where KV memory is not the bottleneck, the gain may be limited. TurboQuant is most relevant when context length, concurrency, or retrieval size makes KV-cache growth a real production problem
Github
You can download the codes on our Github repo, just download and follow the README steps. If need help you can always reach out our team on Discord 🤙
Start your free 30-day trial at regolo.ai and deploy LLMs with complete privacy by design.
👉 Talk with our Engineers or Start your 30 days free →
- TurboQuant: Redefining AI efficiency with extreme compression
- TurboQuant: KV Cache Compression for LLM Inference
- Discord – Share your thoughts
- GitHub Repo – Code of blog articles ready to start
- Follow Us on X @regolo_ai
- Open discussion on our Subreddit Community
Built with ❤️ by the Regolo team. Questions? regolo.ai/contact or chat with us on Discord