If you are deploying LLMs in Europe, “Does it work?” is no longer the question that slows you down.
The real roadblock is whether your inference pipeline is defensible under GDPR, the EU AI Act, and internal governance when prompts contain sensitive data.
Inference data is still data: in real enterprise workloads, prompts and outputs are packed with personal information (names, emails, tickets), confidential contracts and pricing, or regulated health and financial content.
😎 The market is moving decisively toward European, sovereign infrastructure.
Gartner expects European sovereign cloud IaaS spending to jump from roughly 7 billion dollars in 2025 to more than 12 billion in 2026, almost doubling in a single year as organizations seek local control of data and compute. European spending on sovereign cloud is projected to more than triple between 2025 and 2027 as geopolitics and regulation bite.
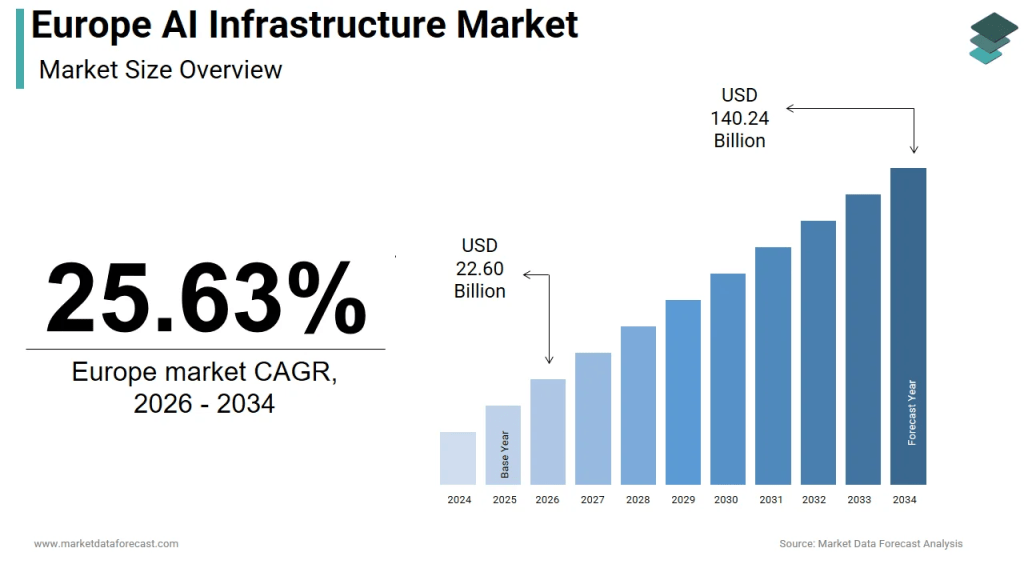
source: Market Data Forecast
The short version: keep inference inside EU jurisdiction, minimize retention, and design your stack so you can prove what happens to data at every step.
If you are exploring sovereign inference today, Regolo runs fully on European data centers in Italy, offers GDPR‑aligned processing and a strict zero‑retention data policy, so your prompts and outputs do not persist after each call.
Why AI data sovereignty is accelerating in Europe
AI data sovereignty is no longer a theoretical policy topic; it is shaping budgets and architectures. Forrester estimates that Europe’s tech spending will exceed 1.5 trillion euro in 2026, with sovereignty becoming a defining theme as organizations put legal and technical constraints on non‑European cloud providers. McKinsey estimates that a “European digital sovereignty” scenario could unlock up to 480 billion euro of value annually by 2030 if Europe combines high AI adoption with sovereign infrastructure and standards.
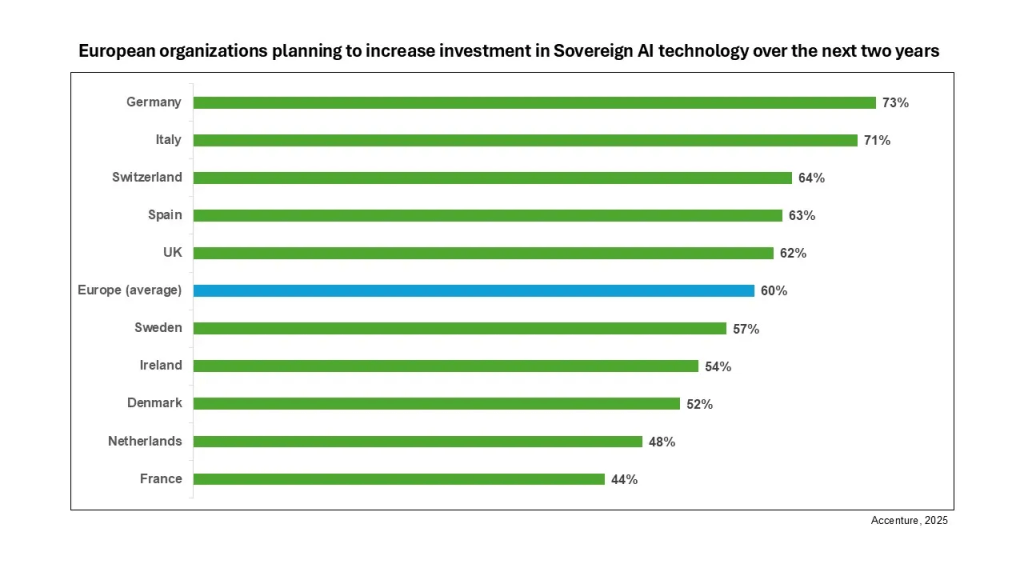
An Accenture study found that 62% of European organizations are explicitly seeking sovereign AI solutions in response to geopolitical uncertainty, with regulated sectors like banking, public services, and utilities leading adoption. In the same survey, 60% of European organizations said they plan to increase investment in sovereign AI technologies in the next two years, with particularly strong intent in Germany, Italy, and Switzerland.
On the supply side, European AI infrastructure is booming. The European AI data center market was valued at about 17.39 billion dollars in 2025 and is expected to expand quickly as more GPU‑optimized facilities come online. In parallel, the Europe generative AI market is forecast to grow from 16.56 billion dollars in 2025 to more than 202.77 billion by 2032, creating huge demand for compliant, low‑latency inference capacity close to users.
The link to the Accenture Study (ITA): https://newsroom.accenture.it/it/news/2025/accenture-sovereignai
English version: https://newsroom.accenture.com/news/2025/europe-seeking-greater-ai-sovereignty-accenture-report-finds
What “AI data sovereignty” really means for LLM inference
AI data sovereignty is your ability to decide where inference data is processed, who can access it, and under which jurisdiction it falls, then demonstrate that control during audits and procurement reviews. In practice, it boils down to three questions:
- Where do prompts and outputs travel, and in which regions are they actually processed.
- What is stored (telemetry, logs, traces, prompts, outputs), and for how long.
- Who can access the system and its data (operators, subprocessors, law enforcement).
Many teams discover that sovereignty starts as a compliance checkbox and quickly becomes a performance and cost advantage. Once you move to a European GPU provider, you can eliminate cross‑border data transfers for EU users, simplify governance, and typically reduce latency for European traffic because inference happens physically closer to your customers.
Sovereignty also de‑risks your long‑term roadmap. As the EU AI Act brings stricter obligations for general‑purpose AI and LLMs, architectures that already keep data local, minimize retention, and offer strong observability will have a much easier time demonstrating compliance to regulators and customers.
GDPR, Schrems II and the EU AI Act: why inference is a data transfer risk
The anxiety about sending inference data outside the EU is not theoretical. If prompts or outputs contain personal data, every call to an external LLM endpoint becomes a regulated processing event, and international transfers must meet GDPR requirements. After the Schrems II ruling, the European Data Protection Board (EDPB) emphasized that organizations must assess each transfer and apply “supplementary measures” where third‑country laws could undermine EU‑level protections, with cloud scenarios explicitly mentioned as high‑risk.
At the same time, the EU AI Act raises the stakes. The AI Act’s core obligations for general‑purpose AI systems, including LLMs, became legally enforceable in August 2025, requiring providers and deployers to meet transparency, documentation, and governance standards or face serious penalties. Fines under the AI Act can reach up to 35 million euro or 7% of global annual turnover, compared to GDPR’s ceiling of 20 million euro or 4% of global revenue.digital.
⚠️ Compliance is already expensive. Research on AI‑GDPR compliance suggests that small to medium‑sized enterprises spend around 1.35 million pounds on compliance, while large enterprises can invest up to 55.59 million pounds in infrastructure, security, assessments, and audits. Recent analyses indicate that mid‑sized organizations can easily spend from 500,000 to over 3 million euro annually just to maintain compliant AI systems once they are in production.
This is why “We don’t train on your prompts” is not enough. You also need to know what is logged, where it is stored, how long it persists, who can query it, and under which jurisdiction potential lawful access requests would be handled.
Sovereign inference vs hyperscaler inference
| Decision area | Typical hyperscaler approach | Sovereign EU inference approach |
|---|---|---|
| Jurisdiction | Global by default; regional settings help but cross‑border legal exposure is scrutinized | EU jurisdiction by design; infrastructure and legal obligations anchored in specific member states |
| Retention posture | Telemetry and logs often enabled by default; prompt logging may persist for 30 days or more | Minimize‑by‑default; we commit to zero retention of prompts and outputs |
| Cost control | Pure consumption models; verbose logging can silently inflate bills | Token‑based billing with real‑time tracking makes spend more predictable |
| Sustainability insight | High‑level carbon calculators, rarely per‑request | Token‑per‑Watt monitoring so teams can track energy per token, |
| Compliance narrative | Complex DPIAs for cross‑border transfers; supplementary measures needed under Schrems II | Simpler DPIAs focused on EU‑only processing and strict data minimization |
Where Regolo fits in your sovereignty roadmap
If your main blocker is “We cannot send prompts to a US hyperscaler,” your fastest path is to choose infrastructure that is European by default and privacy‑first by design. Regolo runs on data centers located in Italy, using Seeweb facilities and renewable energy, and aligns its operations with EU privacy and labor law.
The core of Regolo’s value proposition is a strict zero‑data‑retention architecture. Regolo explains that inference requests are processed in volatile memory using ephemeral containers, then immediately discarded with no storage of prompts or outputs, no long‑term logging of API content, and no reuse for training or fine‑tuning. This goes beyond standard “no training on your data” claims by eliminating residual logs that could otherwise be exposed in breaches or foreign lawful access requests.
From an economics perspective, Regolo offers token‑based billing with real‑time tracking, so teams only pay for the tokens they consume and can watch costs as they scale up agentic architectures or multi‑model workflows. Flat‑rate plans (Core and Boost) provide predictable monthly pricing with high daily token caps, while a 30‑day free trial with no credit card allows you to validate EU‑only inference flows on your actual prompts before you commit.
Regolo also leans into sustainability, exposing token‑per‑Watt monitoring so you can measure energy use per token and tune workloads for lower carbon impact, an increasingly important requirement for European enterprises and public sector buyers. Combined with zero retention and EU‑only processing, this makes Regolo a strong fit for teams that need to satisfy DPOs, CISOs, and sustainability officers at the same time.
Start your 30‑day trial and validate sovereign inference with your own workload on Regolo’s Italian GPU clusters, or book a demo to map your data flows and compliance requirements to a production‑ready architecture.
FAQ
Is LLM inference data considered personal data under GDPR?
If prompts or outputs contain personal data about identified or identifiable individuals, GDPR obligations apply to that processing, including lawful basis, transparency, and security controls. This is true even if your use case feels “internal,” such as support copilots or employee assistants that handle HR tickets and emails.
What is the simplest way to reduce GDPR transfer risk?
The most straightforward approach is to keep inference processing inside EU jurisdiction and minimize retention so that fewer scenarios qualify as international transfers requiring complex Schrems II assessments. When you do need to transfer data to non‑EU providers, you will likely have to rely on Standard Contractual Clauses plus strong technical measures, which adds legal and engineering overhead.
Does “no training on your prompts” solve compliance?
It helps, but it does not address logging, telemetry retention, access control, or cross‑border transfer risk. Regulators and DPOs increasingly expect clarity on what is stored, for how long, and under which jurisdiction law enforcement could potentially request access, not just assurances about model training.
What does “zero retention” mean in practice?
In Regolo’s case, zero retention means that prompts and outputs are neither stored nor logged for later analysis; they are processed in volatile memory and discarded after the response is generated, with no secondary use for training or evaluation. Operational metrics and anonymized aggregates can still be collected, but content itself does not persist in logs or datasets.
Why is sovereign AI infrastructure accelerating in Europe?
Signals include large financing rounds such as Nscale’s 1.4 billion dollar GPU‑backed loan for European GPU cluster deployments and federated projects like Fact8ra that connect AI factories and HPC centers across eight EU member states. Gartner and other analysts expect European sovereign cloud spending to more than triple between 2025 and 2027 as organizations prioritize data and AI sovereignty.
How can we keep observability without storing prompts?
You can log metrics like latency, token counts, error codes, and high‑level usage by application, combined with anonymized request identifiers and model versions. Content logging should be restricted to tightly controlled, time‑limited debug sessions with explicit approvals, and disabled entirely in standard production operation.
Where can I test EU‑based inference quickly?
Regolo offers EU‑only, GPU‑accelerated inference with token‑based pricing, real‑time tracking, and a 30‑day free trial that does not require a credit card, making it easy to pilot sovereign inference on real workloads. You can spin up workloads against Italian data centers and validate latency, quality, and compliance posture before involving heavy procurement processes.
From requirements to running systems
AI data sovereignty is fast becoming a default requirement in Europe, not because teams dislike hyperscalers, but because GDPR, Schrems II, the EU AI Act, and enterprise governance demand tighter control over where inference data goes and what is retained. At the same time, European investment in sovereign AI infrastructure, from AI factories to GPU‑backed data centers, is making it easier than ever to satisfy those requirements without sacrificing performance.
If your LLM roadmap includes sensitive prompts, multi‑agent workflows, or regulated verticals, “EU‑only processing plus minimal retention” is the most straightforward architecture to defend in front of your DPO, CISO, and regulators. Regolo is built for exactly that model, with Italian data centers, zero‑retention inference, token‑based pricing, and energy‑per‑token monitoring that align with Europe’s regulatory and sustainability expectations.
👉 Or book a discovery call with our engineers to explain your case and get a custom offer
- Discord – Share your thoughts
- GitHub Repo – Code of blog articles ready to start
- Follow Us on X @regolo_ai
- Open discussion on our Subreddit Community
🚀 Ready to scale?
Built with ❤️ by the Regolo team. Questions? regolo.ai/contact or chat with us on Discord