brick‑v1-beta is a LoRA‑tuned Qwen3.5‑0.8B classifier from Regolo.ai that labels user queries as easy, medium, or hard in ~20 ms, powering Brick’s semantic router for real‑time LLM routing.
View model
Zero Data Retention in EU Data Center,
powered by 100% green carbon-free energy.
Designed to help AI teams deploy faster, with privacy and effortlessly. Use our Core Models, ready to use via API, or deploy your custom model to be served by our fast European data centers.
Zero Data Retention with full European Data Residency. Your data is never stored or reused, ensuring compliance with GDPR and beyond.
Learn moreGreen datacenters powered by 100% renewable energy sources. AI innovation that respects the planet.
Learn moreOpenAI compatible with zero effort required for integration. Swap your endpoint and keep using the tools you already know.
Learn moreRegolo.ai is built on the OpenAI API standard, the most widely adopted interface in the AI ecosystem. A single, familiar contract to manage text generation, embeddings, vision, and more, covering everything from prototyping to production.
Starting a new project? Use our documentation to get going in minutes. Already have an existing integration? Simply swap your base URL and API key, with no code rewrites and no new patterns to learn. Regolo works as a seamless drop-in replacement.
Leverage the tools and frameworks you already know and trust, including LangChain, LlamaIndex, the official OpenAI SDK, and many more, all without any friction. One standard, every model, zero lock-in.
Start for Free 30 daysimport requests
api_url = "https://api.regolo.ai/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer YOUR_REGOLO_KEY"
}
data = {
"model": "mistral-small-4-119b",
"messages": [
{
"role": "user",
"content": "If a train travels 60 km/h for 2 hours and then 80 km/h for 1.5 hours, what is the total distance covered?"
}
],
"reasoning_effort": "high"
}
response = requests.post(api_url, headers=headers, json=data)
print(response.json())
Ready to use, no cold boots, low latency and free for 30 days.
Explore our growing library of production-ready models.
brick‑v1-beta is a LoRA‑tuned Qwen3.5‑0.8B classifier from Regolo.ai that labels user queries as easy, medium, or hard in ~20 ms, powering Brick’s semantic router for real‑time LLM routing.
gemma‑4‑31B is a 30.7B‑parameter dense multimodal model from Google DeepMind with 256K context, native thinking mode, function calling, and text/image/video support across 140+ languages under Apache 2.0.
Qwen3.5-122B-A10B is a powerful open-weight Mixture-of-Experts (MoE) model from Alibaba's Qwen team, featuring 122 billion total parameters with only 10 billion active per token for efficient performance.
Mistral-Small-4-119B-2603 is a 119B-parameter multimodal MoE model with only 6.5B active parameters per token, delivering top-tier reasoning, coding, and vision performance with a 256k-token context window.
gpt-oss-120b is OpenAI’s flagship open-weight Mixture-of-Experts language model with about 117B parameters and 5.1B active per token, optimized for high‑reasoning, agentic production workloads on a single 80GB GPU and released…
faster‑whisper‑large‑v3 is a CTranslate2‑optimized conversion of OpenAI’s Whisper large‑v3 that delivers high‑accuracy multilingual speech‑to‑text with significantly lower latency and VRAM usage for real‑time and batch transcription.
Apertus‑70B‑2509 is a 70B-parameter, fully open multilingual transformer from the Swiss AI Initiative, trained on 15T compliant tokens and supporting 1,800+ languages with competitive open‑weight benchmark performance.
Llama 3.3 70B Instruct is Meta’s multilingual, instruction-tuned 70B text model for chat, coding, reasoning, and tool-enabled assistants. It supports 128K context, eight officially supported languages, and commercial use under…
The model can be used with sentence-transformers or Hugging Face Transformers, with both integration paths documented on the official model card.
From smart chatbots to automated document pipelines, explore the most popular ways teams put our models to work in production.
Build Retrieval Augmented Generation systems that search across your private documents and deliver accurate, grounded answers. Combine embeddings, reranking, and chat models from a single provider.
Create intelligent chatbots and virtual assistants that handle customer support, sales inquiries, and internal knowledge retrieval with natural, context-aware conversations.
Automate the extraction of structured data from invoices, contracts, and forms using OCR and vision models. Reduce manual data entry and accelerate business workflows.
Generate marketing copy, product descriptions, social media posts, and creative visuals at scale. Use text and image models together to produce complete campaigns.
Convert meetings, podcasts, and customer calls into searchable text. Build transcription pipelines that feed directly into summarization and analysis models.
Power code completion, code review, and debugging tools with models specialized in programming tasks. Accelerate developer productivity and reduce time to production.
Want more customization or need to host a specific model? Bring any model from Hugging Face, pick the GPU configuration that fits, and deploy on dedicated hardware in our European data centers. We download it, load the weights, and serve it. Ready to call in minutes.
Grab the Hugging Face URL of any supported model and add it to your Regolo library. We handle the download and setup on our infrastructure. No manual uploads, no friction.
Choose a GPU instance that matches your model's size and VRAM requirements. From lightweight inference to heavy-duty workloads, you have full control over the resources you need.
Hit deploy and your model goes live on a dedicated endpoint. Scale GPU resources up or down as demand changes. Hourly billing, no long-term commitments, no surprises.
Have questions? Reach out on Discord or read the documentation.
Insights, experiments, and deep-dives into the world of artificial intelligence, straight from the team building it.

As generative AI applications move from fragile prototypes to high-scale production systems, the operational costs of LLM API calls can quickly spiral out of…

The decision of where to execute your large language models is no longer just an infrastructure line item; it is a core architectural and…
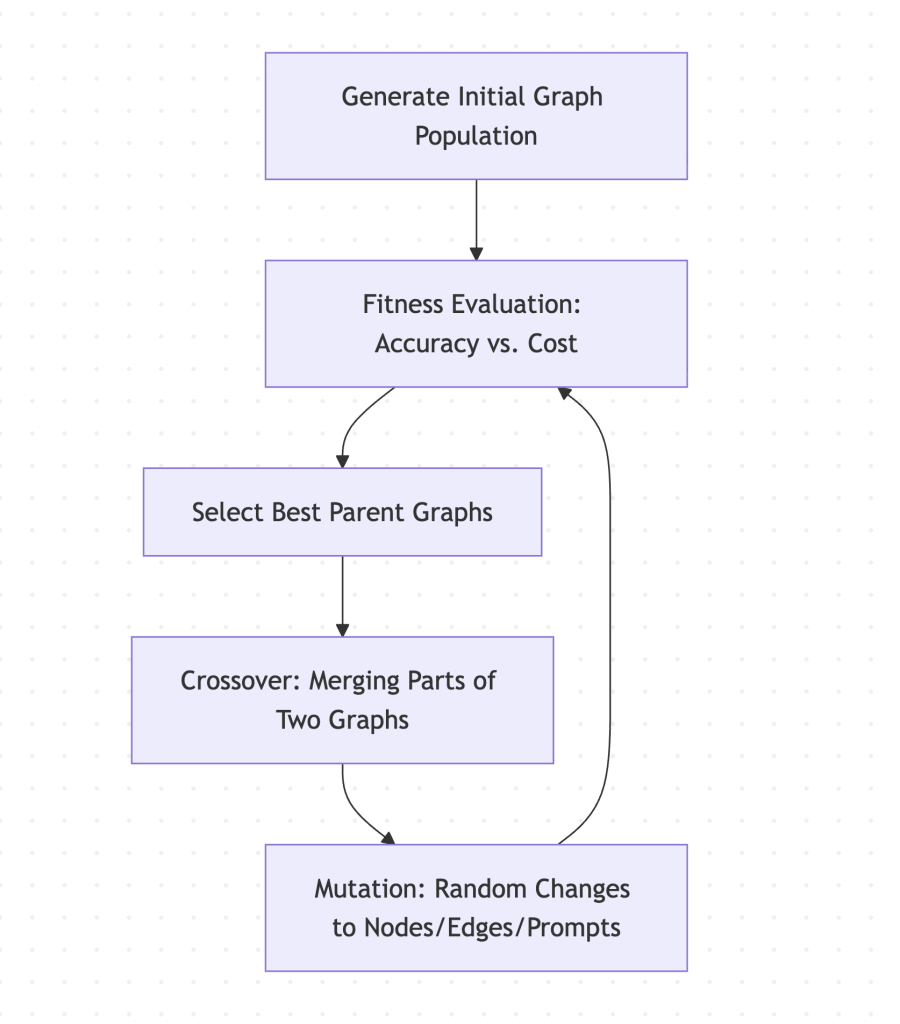
Many teams building production AI applications quickly realize that single-turn prompting inevitably falls apart when faced with intricate, open-ended tasks. We have spent the…
From your first API call to production workloads at scale, Regolo gives you the models, the privacy, and the European infrastructure to build without compromise. No vendor lock-in, no hidden costs.
Have questions or need a custom plan? Join our community on Discord or contact us.


