
It is safe to say that “reasoning” has been one of the most discussed new features of large language models. Since we find it interesting too, it is our will to let you know how to enhance your use of it through regolo.ai/.
What is “reasoning” in models?
A reasoning model is a type of LLM that, instead of providing the first answer it calculates through a statistical process, follows a more complex approach. It generates its response through a ‘chain of thought,’ allowing it to produce a more accurate and contextually appropriate answer.
This is particularly useful when you need the model to ‘reason’ about your input for greater accuracy—especially if your query is highly specific or requires step-by-step problem-solving.
Here is an infographic from OpenAI explaining how a reasoning model works:
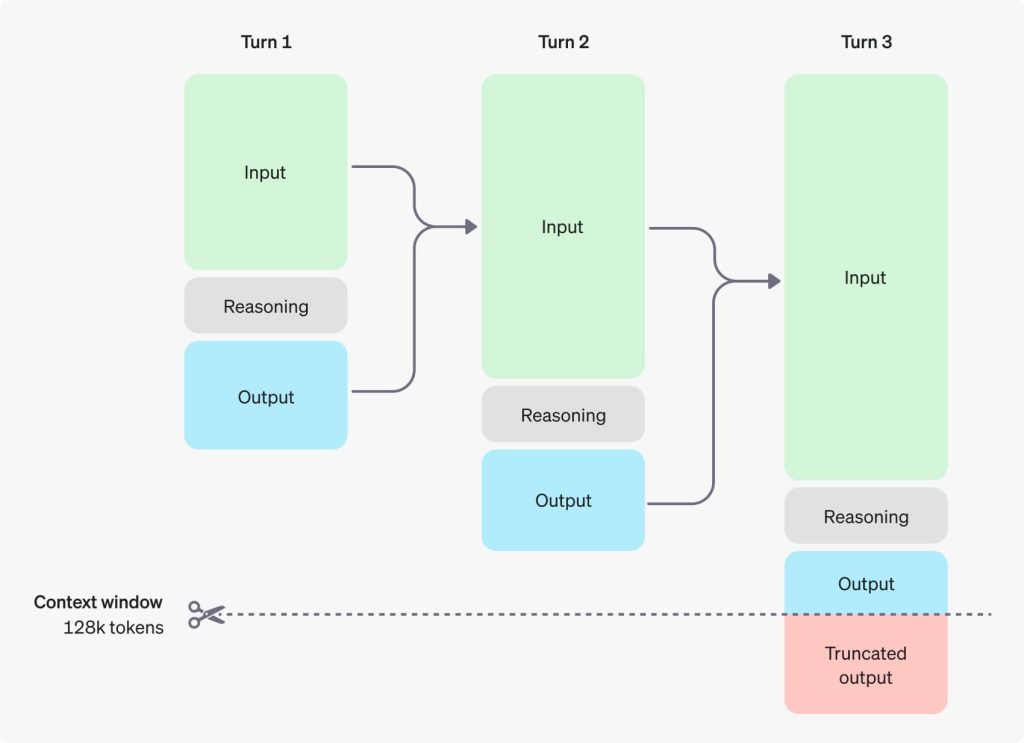
As you can see, this describes how a reasoning model with a context window of 128k tokens works during a chat with a user: on every turn, input and output of the models are preserved, and the reasoning gets discarded (this explains why reasoning tokens often get billed as output tokens).
Which reasoning model did we choose?
When choosing a reasoning model for you to use on Regolo, we consider the most powerful models that can run efficiently on our infrastructure. We want to give you a model that could use for complex tasks and that could still be as general purpose as possible; with this in mind, we have decided to go for one of the most interesting and open models we had access to: “gpt-oss-120b”. The new open-weight model released by openAI, based on a Mixture-of-Experts (MoE) architecture.
Setting up your environment
The first step is to generate a secret key for Regolo:
- Sign in to Regolo and click on ‘Create New Key’
- Decide the name of your key and select the models you want to use (you select “All Models” or only “gpt-oss-120b”)
- Tap on “Create Key” and copy your secret key
Then we want to decide how to interact with the model: said that we support the openAI API standard, you are allowed to use any openAI compatible client.
Making a request
Considering that we want to keep this example as general as possible, here are two equivalent versions of the request, using cURL and our python client.
- cURL (Client for URL) is a widely used command-line tool for making network requests using URLs.We can use it to directly interrogate the regolo endpoints:
curl --request POST \
--url https://api.regolo.ai/v1/chat/completions \
--header 'Authorization: Bearer <Your secret key>' \
--header 'Content-Type: application/json' \
--data '{
"model": "gpt-oss-120b",
"messages": [
{
"role": "user",
"content": "Hi! Could you tell me something about Rome in for lines?"
}
]
}'Code language: PHP (php)- Alternatively, you can interact with regolo.ai/ using our 'regolo' Python module, which utilizes
httpxfor making requests to our endpoints:
# Import regolo module
import regolo
# Setup the module to work with gpt-oss
regolo.default_key = "<Your secret key>"
regolo.default_model = "gpt-oss-120b"
# Instantiate the client
client = regolo.RegoloClient()
client.add_prompt_to_chat(role="user", prompt="Hi! Could you tell me something about Rome in four lines?")
# Perform the request and print the answer
answer = client.run_chat()
print(answer)
Code language: Python (python)Let’s take a look at the output from the previous example in json:
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "Rome, the Eternal City, where marble ruins whisper ancient deeds, \nIts cobblestones echo with the tread of emperors, poets, and saints. \nFrom the soaring dome of St. Peter to the bustling piazza of Trastevere, \nEvery corner cradles a story, a feast of art, cuisine, and timeless charm.",
"role": "assistant",
"reasoning_content": "User wants something about Rome in four lines. Likely a brief poetic description. Provide four lines. Ensure each line separate, maybe a short poem. Provide info. Let's answer."
}
}Code language: JSON / JSON with Comments (json)
We can easily see how the model output is split between the “reasoning_content” field, containing the output of the reasoning, and the “content” field, containing the actual output of the model.
Final words
To summarize, we explored how reasoning models work and how to use them with regolo.ai/.
If you’d like for us to write about some topics, or want clarifying on how to interact with particular services through regolo, you can always reach to us through our official channels.
If you want to know more about using reasoning in LLMs, here are some useful links: